Home
Disclaimer: this repo is 2GB as of this writing and growing fast.... download at your own discretion.... if you want to download it but don't have the space the icloud storage section located at the top of the deployed website contains the entire contents of this repo as well as bonus materials!
hi2
- Closure-and-Scope
- Callbacks
- General Notes
- Review-Of-Previous-Concepts
- Array-CB-Methods
- Mutability
- Objects
- Reiew
- Scope
- Understanding By Example
- Spread and Rest



PlatformsProgramming LanguagesFront-End DevelopmentBack-End DevelopmentComputer ScienceBig DataTheoryBooksEditorsGamingDevelopment EnvironmentEntertainmentDatabasesMediaLearnSecurityContent Management SystemsHardwareBusinessWorkNetworkingDecentralized SystemsHigher EducationEventsTestingMiscellaneousRelated
-
Node.js - Async non-blocking event-driven JavaScript runtime built on Chrome's V8 JavaScript engine.)
- Cross-Platform - Writing cross-platform code on Node.js.)
- Frontend Development)
- iOS - Mobile operating system for Apple phones and tablets.)
- Android - Mobile operating system developed by Google.)
- IoT & Hybrid Apps)
- Electron - Cross-platform native desktop apps using JavaScript/HTML/CSS.)
- Cordova - JavaScript API for hybrid apps.)
- React Native - JavaScript framework for writing natively rendering mobile apps for iOS and Android.)
- Xamarin - Mobile app development IDE, testing, and distribution.)
-
Linux)
- Containers)
- eBPF - Virtual machine that allows you to write more efficient and powerful tracing and monitoring for Linux systems.)
- Arch-based Projects - Linux distributions and projects based on Arch Linux.)
- macOS - Operating system for Apple's Mac computers.)
- watchOS - Operating system for the Apple Watch.)
- JVM)
- Salesforce)
- Amazon Web Services)
- Windows)
- IPFS - P2P hypermedia protocol.)
- Fuse - Mobile development tools.)
- Heroku - Cloud platform as a service.)
- Raspberry Pi - Credit card-sized computer aimed at teaching kids programming, but capable of a lot more.)
- Qt - Cross-platform GUI app framework.)
- WebExtensions - Cross-browser extension system.)
- RubyMotion - Write cross-platform native apps for iOS, Android, macOS, tvOS, and watchOS in Ruby.)
- Smart TV - Create apps for different TV platforms.)
- GNOME - Simple and distraction-free desktop environment for Linux.)
- KDE - A free software community dedicated to creating an open and user-friendly computing experience.)
- .NET)
- Amazon Alexa - Virtual home assistant.)
- DigitalOcean - Cloud computing platform designed for developers.)
- Flutter - Google's mobile SDK for building native iOS and Android apps from a single codebase written in Dart.)
- Home Assistant - Open source home automation that puts local control and privacy first.)
- IBM Cloud - Cloud platform for developers and companies.)
- Firebase - App development platform built on Google Cloud Platform.)
- Robot Operating System 2.0 - Set of software libraries and tools that help you build robot apps.)
- Adafruit IO - Visualize and store data from any device.)
- Cloudflare - CDN, DNS, DDoS protection, and security for your site.)
- Actions on Google - Developer platform for Google Assistant.)
- ESP - Low-cost microcontrollers with WiFi and broad IoT applications.)
- Deno - A secure runtime for JavaScript and TypeScript that uses V8 and is built in Rust.)
- DOS - Operating system for x86-based personal computers that was popular during the 1980s and early 1990s.)
- Nix - Package manager for Linux and other Unix systems that makes package management reliable and reproducible.) )
)
-
JavaScript)
- Promises)
- Standard Style - Style guide and linter.)
- Must Watch Talks)
- Tips)
- Network Layer)
- Micro npm Packages)
- Mad Science npm Packages - Impossible sounding projects that exist.)
- Maintenance Modules - For npm packages.)
- npm - Package manager.)
- AVA - Test runner.)
- ESLint - Linter.)
- Functional Programming)
- Observables)
- npm scripts - Task runner.)
- 30 Seconds of Code - Code snippets you can understand in 30 seconds.)
- Ponyfills - Like polyfills but without overriding native APIs.)
- Swift - Apple's compiled programming language that is secure, modern, programmer-friendly, and fast.)
-
Python - General-purpose programming language designed for readability.)
- Asyncio - Asynchronous I/O in Python 3.)
- Scientific Audio - Scientific research in audio/music.)
- CircuitPython - A version of Python for microcontrollers.)
- Data Science - Data analysis and machine learning.)
- Typing - Optional static typing for Python.)
- MicroPython - A lean and efficient implementation of Python 3 for microcontrollers.)
- Rust)
- Haskell)
- PureScript)
- Go)
-
Scala)
- Scala Native - Optimizing ahead-of-time compiler for Scala based on LLVM.)
- Ruby)
- Clojure)
- ClojureScript)
- Elixir)
- Elm)
- Erlang)
- Julia - High-level dynamic programming language designed to address the needs of high-performance numerical analysis and computational science.)
- Lua)
- C)
- C/C++ - General-purpose language with a bias toward system programming and embedded, resource-constrained software.)
- R - Functional programming language and environment for statistical computing and graphics.)
- D)
- Common Lisp - Powerful dynamic multiparadigm language that facilitates iterative and interactive development.)
- Perl)
- Groovy)
- Dart)
- Java - Popular secure object-oriented language designed for flexibility to "write once, run anywhere".)
- Kotlin)
- OCaml)
- ColdFusion)
- Fortran)
-
PHP - Server-side scripting language.)
- Composer - Package manager.)
- Pascal)
- AutoHotkey)
- AutoIt)
- Crystal)
- Frege - Haskell for the JVM.)
- CMake - Build, test, and package software.)
- ActionScript 3 - Object-oriented language targeting Adobe AIR.)
- Eta - Functional programming language for the JVM.)
- Idris - General purpose pure functional programming language with dependent types influenced by Haskell and ML.)
- Ada/SPARK - Modern programming language designed for large, long-lived apps where reliability and efficiency are essential.)
- Q# - Domain-specific programming language used for expressing quantum algorithms.)
- Imba - Programming language inspired by Ruby and Python and compiles to performant JavaScript.)
- Vala - Programming language designed to take full advantage of the GLib and GNOME ecosystems, while preserving the speed of C code.)
- Coq - Formal language and environment for programming and specification which facilitates interactive development of machine-checked proofs.)
- V - Simple, fast, safe, compiled language for developing maintainable software.) )
)
- ES6 Tools)
- Web Performance Optimization)
- Web Tools)
- CSS - Style sheet language that specifies how HTML elements are displayed on screen.)
-
React - App framework.)
- Relay - Framework for building data-driven React apps.)
- React Hooks - A new feature that lets you use state and other React features without writing a class.)
- Web Components)
- Polymer - JavaScript library to develop Web Components.)
- Angular - App framework.)
- Backbone - App framework.)
- HTML5 - Markup language used for websites & web apps.)
- SVG - XML-based vector image format.)
- Canvas)
- KnockoutJS - JavaScript library.)
- Dojo Toolkit - JavaScript toolkit.)
- Inspiration)
- Ember - App framework.)
- Android UI)
- iOS UI)
- Meteor)
- BEM)
- Flexbox)
- Web Typography)
- Web Accessibility)
- Material Design)
- D3 - Library for producing dynamic, interactive data visualizations.)
- Emails)
-
jQuery - Easy to use JavaScript library for DOM manipulation.)
- Tips)
- Web Audio)
- Offline-First)
- Static Website Services)
- Cycle.js - Functional and reactive JavaScript framework.)
- Text Editing)
- Motion UI Design)
- Vue.js - App framework.)
- Marionette.js - App framework.)
- Aurelia - App framework.)
- Charting)
- Ionic Framework 2)
- Chrome DevTools)
- PostCSS - CSS tool.)
- Draft.js - Rich text editor framework for React.)
- Service Workers)
- Progressive Web Apps)
- choo - App framework.)
- Redux - State container for JavaScript apps.)
- webpack - Module bundler.)
- Browserify - Module bundler.)
- Sass - CSS preprocessor.)
- Ant Design - Enterprise-class UI design language.)
- Less - CSS preprocessor.)
- WebGL - JavaScript API for rendering 3D graphics.)
- Preact - App framework.)
- Progressive Enhancement)
- Next.js - Framework for server-rendered React apps.)
- lit-html - HTML templating library for JavaScript.)
- JAMstack - Modern web development architecture based on client-side JavaScript, reusable APIs, and prebuilt markup.)
- WordPress-Gatsby - Web development technology stack with WordPress as a back end and Gatsby as a front end.)
- Mobile Web Development - Creating a great mobile web experience.)
- Storybook - Development environment for UI components.)
- Blazor - .NET web framework using C#/Razor and HTML that runs in the browser with WebAssembly.)
- PageSpeed Metrics - Metrics to help understand page speed and user experience.)
- Tailwind CSS - Utility-first CSS framework for rapid UI development.)
- Seed - Rust framework for creating web apps running in WebAssembly.)
- Web Performance Budget - Techniques to ensure certain performance metrics for a website.)
- Web Animation - Animations in the browser with JavaScript, CSS, SVG, etc.)
- Yew - Rust framework inspired by Elm and React for creating multi-threaded frontend web apps with WebAssembly.)
- Material-UI - Material Design React components for faster and easier web development.)
- Building Blocks for Web Apps - Standalone features to be integrated into web apps.)
- Svelte - App framework.)
- Design systems - Collection of reusable components, guided by rules that ensure consistency and speed.) )
)
- Flask - Python framework.)
- Docker)
- Vagrant - Automation virtual machine environment.)
- Pyramid - Python framework.)
- Play1 Framework)
- CakePHP - PHP framework.)
- Symfony - PHP framework.)
-
Laravel - PHP framework.)
- Education)
- TALL Stack - Full-stack development solution featuring libraries built by the Laravel community.)
-
Rails - Web app framework for Ruby.)
- Gems - Packages.)
- Phalcon - PHP framework.)
-
Useful
.htaccessSnippets) - nginx - Web server.)
- Dropwizard - Java framework.)
- Kubernetes - Open-source platform that automates Linux container operations.)
- Lumen - PHP micro-framework.)
- Serverless Framework - Serverless computing and serverless architectures.)
- Apache Wicket - Java web app framework.)
- Vert.x - Toolkit for building reactive apps on the JVM.)
- Terraform - Tool for building, changing, and versioning infrastructure.)
- Vapor - Server-side development in Swift.)
- Dash - Python web app framework.)
- FastAPI - Python web app framework.)
- CDK - Open-source software development framework for defining cloud infrastructure in code.)
- IAM - User accounts, authentication and authorization.) )
)
- University Courses)
- Data Science)
-
Machine Learning)
- Tutorials)
- ML with Ruby - Learning, implementing, and applying Machine Learning using Ruby.)
- Core ML Models - Models for Apple's machine learning framework.)
- H2O - Open source distributed machine learning platform written in Java with APIs in R, Python, and Scala.)
- Software Engineering for Machine Learning - From experiment to production-level machine learning.)
- AI in Finance - Solving problems in finance with machine learning.)
- JAX - Automatic differentiation and XLA compilation brought together for high-performance machine learning research.)
-
Speech and Natural Language Processing)
- Spanish)
- NLP with Ruby)
- Question Answering - The science of asking and answering in natural language with a machine.)
- Natural Language Generation - Generation of text used in data to text, conversational agents, and narrative generation applications.)
- Linguistics)
-
Cryptography)
- Papers - Theory basics for using cryptography by non-cryptographers.)
- Computer Vision)
-
Deep Learning - Neural networks.)
- TensorFlow - Library for machine intelligence.)
- TensorFlow.js - WebGL-accelerated machine learning JavaScript library for training and deploying models.)
- TensorFlow Lite - Framework that optimizes TensorFlow models for on-device machine learning.)
- Papers - The most cited deep learning papers.)
- Education)
- Deep Vision)
- Open Source Society University)
- Functional Programming)
- Empirical Software Engineering - Evidence-based research on software systems.)
- Static Analysis & Code Quality)
- Information Retrieval - Learn to develop your own search engine.)
- Quantum Computing - Computing which utilizes quantum mechanics and qubits on quantum computers.) )
)
- Big Data)
- Public Datasets)
- Hadoop - Framework for distributed storage and processing of very large data sets.)
- Data Engineering)
- Streaming)
- Apache Spark - Unified engine for large-scale data processing.)
- Qlik - Business intelligence platform for data visualization, analytics, and reporting apps.)
- Splunk - Platform for searching, monitoring, and analyzing structured and unstructured machine-generated big data in real-time.) )
)
- Papers We Love)
- Talks)
-
Algorithms)
- Education - Learning and practicing.)
- Algorithm Visualizations)
- Artificial Intelligence)
- Search Engine Optimization)
- Competitive Programming)
- Math)
- Recursion Schemes - Traversing nested data structures.) )
)
)
- Sublime Text)
- Vim)
- Emacs)
- Atom - Open-source and hackable text editor.)
- Visual Studio Code - Cross-platform open-source text editor.) )
)
- Game Development)
- Game Talks)
- Godot - Game engine.)
- Open Source Games)
- Unity - Game engine.)
- Chess)
- LÖVE - Game engine.)
- PICO-8 - Fantasy console.)
- Game Boy Development)
- Construct 2 - Game engine.)
- Gideros - Game engine.)
- Minecraft - Sandbox video game.)
- Game Datasets - Materials and datasets for Artificial Intelligence in games.)
- Haxe Game Development - A high-level strongly typed programming language used to produce cross-platform native code.)
- libGDX - Java game framework.)
- PlayCanvas - Game engine.)
- Game Remakes - Actively maintained open-source game remakes.)
- Flame - Game engine for Flutter.)
- Discord Communities - Chat with friends and communities.)
- CHIP-8 - Virtual computer game machine from the 70s.)
- Games of Coding - Learn a programming language by making games.) )
)
- Quick Look Plugins - For macOS.)
- Dev Env)
- Dotfiles)
- Shell)
- Fish - User-friendly shell.)
- Command-Line Apps)
- ZSH Plugins)
-
GitHub - Hosting service for Git repositories.)
- Browser Extensions)
- Cheat Sheet)
- Pinned Gists - Dynamic pinned gists for your GitHub profile.)
- Git Cheat Sheet & Git Flow)
- Git Tips)
-
Git Add-ons - Enhance the
gitCLI.) -
Git Hooks - Scripts for automating tasks during
gitworkflows.) - SSH)
- FOSS for Developers)
- Hyper - Cross-platform terminal app built on web technologies.)
- PowerShell - Cross-platform object-oriented shell.)
- Alfred Workflows - Productivity app for macOS.)
- Terminals Are Sexy)
- GitHub Actions - Create tasks to automate your workflow and share them with others on GitHub.) )
)
- Science Fiction - Scifi.)
- Fantasy)
- Podcasts)
- Email Newsletters)
- IT Quotes) )
)
- Database)
- MySQL)
- SQLAlchemy)
- InfluxDB)
- Neo4j)
- MongoDB - NoSQL database.)
- RethinkDB)
- TinkerPop - Graph computing framework.)
- PostgreSQL - Object-relational database.)
- CouchDB - Document-oriented NoSQL database.)
- HBase - Distributed, scalable, big data store.)
- NoSQL Guides - Help on using non-relational, distributed, open-source, and horizontally scalable databases.)
- Contexture - Abstracts queries/filters and results/aggregations from different backing data stores like ElasticSearch and MongoDB.)
- Database Tools - Everything that makes working with databases easier.)
- Grakn - Logical database to organize large and complex networks of data as one body of knowledge.) )
)
- Creative Commons Media)
- Fonts)
- Codeface - Text editor fonts.)
- Stock Resources)
- GIF - Image format known for animated images.)
- Music)
- Open Source Documents)
- Audio Visualization)
- Broadcasting)
- Pixel Art - Pixel-level digital art.)
- FFmpeg - Cross-platform solution to record, convert and stream audio and video.)
- Icons - Downloadable SVG/PNG/font icon projects.)
- Audiovisual - Lighting, audio and video in professional environments.) )
)
- CLI Workshoppers - Interactive tutorials.)
- Learn to Program)
- Speaking)
- Tech Videos)
- Dive into Machine Learning)
- Computer History)
- Programming for Kids)
- Educational Games - Learn while playing.)
- JavaScript Learning)
- CSS Learning - Mainly about CSS - the language and the modules.)
- Product Management - Learn how to be a better product manager.)
- Roadmaps - Gives you a clear route to improve your knowledge and skills.)
- YouTubers - Watch video tutorials from YouTubers that teach you about technology.) )
)
- Application Security)
- Security)
- CTF - Capture The Flag.)
- Malware Analysis)
- Android Security)
- Hacking)
- Honeypots - Deception trap, designed to entice an attacker into attempting to compromise the information systems in an organization.)
- Incident Response)
- Vehicle Security and Car Hacking)
- Web Security - Security of web apps & services.)
- Lockpicking - The art of unlocking a lock by manipulating its components without the key.)
- Cybersecurity Blue Team - Groups of individuals who identify security flaws in information technology systems.)
- Fuzzing - Automated software testing technique that involves feeding pseudo-randomly generated input data.)
- Embedded and IoT Security)
- GDPR - Regulation on data protection and privacy for all individuals within EU.)
- DevSecOps - Integration of security practices into DevOps.) )
)
- Umbraco)
- Refinery CMS - Ruby on Rails CMS.)
- Wagtail - Django CMS focused on flexibility and user experience.)
- Textpattern - Lightweight PHP-based CMS.)
- Drupal - Extensible PHP-based CMS.)
- Craft CMS - Content-first CMS.)
- Sitecore - .NET digital marketing platform that combines CMS with tools for managing multiple websites.)
- Silverstripe CMS - PHP MVC framework that serves as a classic or headless CMS.) )
)
- Robotics)
- Internet of Things)
- Electronics - For electronic engineers and hobbyists.)
- Bluetooth Beacons)
- Electric Guitar Specifications - Checklist for building your own electric guitar.)
- Plotters - Computer-controlled drawing machines and other visual art robots.)
- Robotic Tooling - Free and open tools for professional robotic development.)
- LIDAR - Sensor for measuring distances by illuminating the target with laser light.) )
)
- Open Companies)
- Places to Post Your Startup)
- OKR Methodology - Goal setting & communication best practices.)
- Leading and Managing - Leading people and being a manager in a technology company/environment.)
- Indie - Independent developer businesses.)
- Tools of the Trade - Tools used by companies on Hacker News.)
- Clean Tech - Fighting climate change with technology.)
- Wardley Maps - Provides high situational awareness to help improve strategic planning and decision making.)
- Social Enterprise - Building an organization primarily focused on social impact that is at least partially self-funded.)
- Engineering Team Management - How to transition from software development to engineering management.)
- Developer-First Products - Products that target developers as the user.) )
)
- Slack - Team collaboration.)
- Remote Jobs)
- Productivity)
- Niche Job Boards)
- Programming Interviews)
- Code Review - Reviewing code.)
- Creative Technology - Businesses & groups that specialize in combining computing, design, art, and user experience.) )
)
- Software-Defined Networking)
- Network Analysis)
- PCAPTools)
- Real-Time Communications - Network protocols for near simultaneous exchange of media and data.) )
)
- Bitcoin - Bitcoin services and tools for software developers.)
- Ripple - Open source distributed settlement network.)
- Non-Financial Blockchain - Non-financial blockchain applications.)
- Mastodon - Open source decentralized microblogging network.)
- Ethereum - Distributed computing platform for smart contract development.)
- Blockchain AI - Blockchain projects for artificial intelligence and machine learning.)
- EOSIO - A decentralized operating system supporting industrial-scale apps.)
- Corda - Open source blockchain platform designed for business.)
- Waves - Open source blockchain platform and development toolset for Web 3.0 apps and decentralized solutions.)
- Substrate - Framework for writing scalable, upgradeable blockchains in Rust.) )
)
- Computational Neuroscience - A multidisciplinary science which uses computational approaches to study the nervous system.)
- Digital History - Computer-aided scientific investigation of history.)
- Scientific Writing - Distraction-free scientific writing with Markdown, reStructuredText and Jupyter notebooks.) )
)
- Creative Tech Events - Events around the globe for creative coding, tech, design, music, arts and cool stuff.)
- Events in Italy - Tech-related events in Italy.)
- Events in the Netherlands - Tech-related events in the Netherlands.) )
)
- Testing - Software testing.)
- Visual Regression Testing - Ensures changes did not break the functionality or style.)
- Selenium - Open-source browser automation framework and ecosystem.)
- Appium - Test automation tool for apps.)
- TAP - Test Anything Protocol.)
- JMeter - Load testing and performance measurement tool.)
- k6 - Open-source, developer-centric performance monitoring and load testing solution.)
- Playwright - Node.js library to automate Chromium, Firefox and WebKit with a single API.)
- Quality Assurance Roadmap - How to start & build a career in software testing.) )
)
- JSON - Text based data interchange format.)
- CSV - A text file format that stores tabular data and uses a comma to separate values.)
- Discounts for Student Developers)
- Radio)
- Awesome - Recursion illustrated.)
- Analytics)
- REST)
- Continuous Integration and Continuous Delivery)
- Services Engineering)
- Free for Developers)
- Answers - Stack Overflow, Quora, etc.)
- Sketch - Design app for macOS.)
- Boilerplate Projects)
- Readme)
- Design and Development Guides)
- Software Engineering Blogs)
- Self Hosted)
- FOSS Production Apps)
- Gulp - Task runner.)
- AMA - Ask Me Anything.)
- Open Source Photography)
- OpenGL - Cross-platform API for rendering 2D and 3D graphics.)
- GraphQL)
- Transit)
- Research Tools)
- Data Visualization)
- Social Media Share Links)
- Microservices)
- Unicode - Unicode standards, quirks, packages and resources.)
- Beginner-Friendly Projects)
- Katas)
- Tools for Activism)
- Citizen Science - For community-based and non-institutional scientists.)
- MQTT - "Internet of Things" connectivity protocol.)
- Hacking Spots)
- For Girls)
- Vorpal - Node.js CLI framework.)
- Vulkan - Low-overhead, cross-platform 3D graphics and compute API.)
- LaTeX - Typesetting language.)
- Economics - An economist's starter kit.)
- Funny Markov Chains)
- Bioinformatics)
- Cheminformatics - Informatics techniques applied to problems in chemistry.)
- Colorful - Choose your next color scheme.)
- Steam - Digital distribution platform.)
- Bots - Building bots.)
- Site Reliability Engineering)
- Empathy in Engineering - Building and promoting more compassionate engineering cultures.)
- DTrace - Dynamic tracing framework.)
- Userscripts - Enhance your browsing experience.)
- Pokémon - Pokémon and Pokémon GO.)
- ChatOps - Managing technical and business operations through a chat.)
- Falsehood - Falsehoods programmers believe in.)
- Domain-Driven Design - Software development approach for complex needs by connecting the implementation to an evolving model.)
- Quantified Self - Self-tracking through technology.)
- SaltStack - Python-based config management system.)
- Web Design - For digital designers.)
- Creative Coding - Programming something expressive instead of something functional.)
- No-Login Web Apps - Web apps that work without login.)
- Free Software - Free as in freedom.)
- Framer - Prototyping interactive UI designs.)
- Markdown - Markup language.)
- Dev Fun - Funny developer projects.)
- Healthcare - Open source healthcare software for facilities, providers, developers, policy experts, and researchers.)
- Magento 2 - Open Source eCommerce built with PHP.)
- TikZ - Graph drawing packages for TeX/LaTeX/ConTeXt.)
- Neuroscience - Study of the nervous system and brain.)
- Ad-Free - Ad-free alternatives.)
- Esolangs - Programming languages designed for experimentation or as jokes rather than actual use.)
- Prometheus - Open-source monitoring system.)
- Homematic - Smart home devices.)
- Ledger - Double-entry accounting on the command-line.)
- Web Monetization - A free open web standard service that allows you to send money directly in your browser.)
- Uncopyright - Public domain works.)
- Crypto Currency Tools & Algorithms - Digital currency where encryption is used to regulate the generation of units and verify transfers.)
- Diversity - Creating a more inclusive and diverse tech community.)
- Open Source Supporters - Companies that offer their tools and services for free to open source projects.)
- Design Principles - Create better and more consistent designs and experiences.)
- Theravada - Teachings from the Theravada Buddhist tradition.)
- inspectIT - Open source Java app performance management tool.)
- Open Source Maintainers - The experience of being an open source maintainer.)
- Calculators - Calculators for every platform.)
- Captcha - A type of challenge-response test used in computing to determine whether or not the user is human.)
- Jupyter - Create and share documents that contain code, equations, visualizations and narrative text.)
- FIRST Robotics Competition - International high school robotics championship.)
- Humane Technology - Open source projects that help improve society.)
- Speakers - Conference and meetup speakers in the programming and design community.)
- Board Games - Table-top gaming fun for all.)
- Software Patreons - Fund individual programmers or the development of open source projects.)
- Parasite - Parasites and host-pathogen interactions.)
- Food - Food-related projects on GitHub.)
- Mental Health - Mental health awareness and self-care in the software industry.)
- Bitcoin Payment Processors - Start accepting Bitcoin.)
- Scientific Computing - Solving complex scientific problems using computers.)
- Amazon Sellers)
- Agriculture - Open source technology for farming and gardening.)
- Product Design - Design a product from the initial concept to production.)
- Prisma - Turn your database into a GraphQL API.)
- Software Architecture - The discipline of designing and building software.)
- Connectivity Data and Reports - Better understand who has access to telecommunication and internet infrastructure and on what terms.)
- Stacks - Tech stacks for building different apps and features.)
- Cytodata - Image-based profiling of biological phenotypes for computational biologists.)
- IRC - Open source messaging protocol.)
- Advertising - Advertising and programmatic media for websites.)
- Earth - Find ways to resolve the climate crisis.)
- Naming - Naming things in computer science done right.)
- Biomedical Information Extraction - How to extract information from unstructured biomedical data and text.)
- Web Archiving - An effort to preserve the Web for future generations.)
- WP-CLI - Command-line interface for WordPress.)
- Credit Modeling - Methods for classifying credit applicants into risk classes.)
- Ansible - A Python-based, open source IT configuration management and automation platform.)
- Biological Visualizations - Interactive visualization of biological data on the web.)
- QR Code - A type of matrix barcode that can be used to store and share a small amount of information.)
- Veganism - Making the plant-based lifestyle easy and accessible.)
- Translations - The transfer of the meaning of a text from one language to another.) )
)
- All Awesome Lists - All the Awesome lists on GitHub.)
- Awesome Indexed - Search the Awesome dataset.)
- Awesome Search - Quick search for Awesome lists.)
- StumbleUponAwesome - Discover random pages from the Awesome dataset using a browser extension.)
- Awesome CLI - A simple command-line tool to dive into Awesome lists.)
- Awesome Viewer - A visualizer for all of the above Awesome lists.) ) Created 1 minute ago | Updated 58 seconds ago) )
1-projects/Atomic-Design-Solution-master/dogs/
Table of Contents generated with DocToc
- Table of Contents
- Updating to New Releases
- Sending Feedback
- Folder Structure
- Available Scripts
- Supported Browsers
- Supported Language Features and Polyfills
- Syntax Highlighting in the Editor
- Displaying Lint Output in the Editor
- Debugging in the Editor
- Formatting Code Automatically
- Changing the Page
<title> - Installing a Dependency
- Importing a Component
- Code Splitting
- Adding a Stylesheet
- Post-Processing CSS
- Adding a CSS Preprocessor (Sass, Less etc.)
- Adding Images, Fonts, and Files
-
Using the
publicFolder - Using Global Variables
- Adding Bootstrap
- Adding Flow
- Adding a Router
- Adding Custom Environment Variables
- Can I Use Decorators?
- Fetching Data with AJAX Requests
- Integrating with an API Backend
- Proxying API Requests in Development
- Using HTTPS in Development
- Generating Dynamic
<meta>Tags on the Server - Pre-Rendering into Static HTML Files
- Injecting Data from the Server into the Page
-
Running Tests
- Filename Conventions
- Command Line Interface
- Version Control Integration
- Writing Tests
- Testing Components
- Using Third Party Assertion Libraries
- Initializing Test Environment
- Focusing and Excluding Tests
- Coverage Reporting
- Continuous Integration
- On CI servers
- On your own environment
- Disabling jsdom
- Snapshot Testing
- Editor Integration
- Debugging Tests
- Developing Components in Isolation
- Publishing Components to npm
- Making a Progressive Web App
- Analyzing the Bundle Size
- Deployment
- Advanced Configuration
- Troubleshooting
- Alternatives to Ejecting
- Something Missing?
1-projects/Atomic-Design-Solution-master/
Table of Contents generated with DocToc
- Routing with React Router
- Axios for making HTTP requests
- JavaScript Promises
- Atomic Design
In this create-react-app initialized app, you will be working with the provided UI library, which has been developed based on Atomic Design principles. This is not the only way to design and organize your components, but it will serve as an example of a very strong option.
The app you will be finishing is an app that lists a few dog breeds, shows an image, and provides links to view their sub-breeds.
You are given the atoms, molecules, organisms, and templates needed to build out this app. You will just need to consume them in your pages Breeds.js and SubBreeds.js. All of your HTTP requests should be made from inside of the page files.
-
Requirements for
Breeds.js- Title should be "Breeds"
- Show a list of dog breeds
- Each list item should be a link to a
SubBreedpage that shows the sub-breed details - Show an image of the first dog breed in the list, with that breed as a title for the image
- use the provided method
filterBreedsor any modification of it to limit the list (This is to make sure that the breeds we show actually have sub-breeds. Make sure you still make the initial get requests for the list of dogs first though as part of the assignment exercise)
-
Requirements for
SubBreeds.js- Title should be "Sub-breeds"
- Subtitle should be the given breed
- Show a list of sub-breeds for the given breed
- Show an image of the first sub-breed in the list, with that sub-breed as a title for the image
- Dog Breed API: https://dog.ceo/dog-api/
- Atomic Design: http://bradfrost.com/blog/post/atomic-web-design/
- Component Folder Pattern: https://medium.com/styled-components/component-folder-pattern-ee42df37ec68
- Modified Atomic Design: https://medium.com/@yejodido/atomic-components-managing-dynamic-react-components-using-atomic-design-part-1-5f07451f261f
1-projects/Basic-JavaScript-master/
Table of Contents generated with DocToc
- ES6
- Const vs Let vs Var
- Lambda/Arrow functions
- Object Destructuring
- This project should be very familiar to you. You have already suffered through the logic behind a lot of these expressions/functions.
- We're excited to give you something you've already worked on, but to now just convert the code into ES6 syntax.
- Learning to program is all about repetition. So teaching you a new concept with material that you've already learned will help you solidify the material and also teach you new concepts along the way.
- Project files 1 - 3 are all that need to be completed for this assignment. And Project-4 is Extra Credit.
- Please have fun!
- Fork and clone this repo.
-
cdinto this project and Run the commandnpm ito install needed node packages. - Run the command
npm testto run the tests. - Work through the files and make the tests pass.
- Submit a pull request when you are finished and we will review your code.
1-projects/Client-Auth-Solution-master/
Table of Contents generated with DocToc
redux-thunkcors
- Redux Thunk
- localStorage
- axios's config object
- http headers
Clone down this project. Run npm i.
Start your MongoDB server by running mongod from the command line.
Start the server (on the solution branch) of the LS-Auth repository.
Complete the SignUp component. When the user fills out the form you should send and
axios POST request to the server to save the user to the database. If successful then you
should save the provided JWT to localStorage and then redirect the user to /users.
User the existing code as a reference.
You will also need to make sure that your server is using the cors middleware.
Instructions for adding cors:
npm i --save corsconst cors = require('cors');app.use(cors());
1-projects/Components-BEM-Solution-master/
Table of Contents generated with DocToc
Topics:
- Naming Conventions
- BEM
- Constructors with ES6 class syntax
You will be turning the wireframes provided in the markups directory into a page.
Using BEM, create the page with three components: Section, Box, and Dropdown.
Using ES6 class constructors, complete the Dropdown component functionality.
Here is some Lorem Ipsum text:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Fusce risus nibh, gravida nec felis quis, facilisis facilisis lectus. Nulla ac orci pretium, condimentum orci quis, accumsan nisi. Aliquam erat volutpat. Curabitur cursus mattis libero, at viverra risus hendrerit quis. Fusce imperdiet tristique tortor non tincidunt. Mauris accumsan urna nec augue feugiat porta. Proin vitae magna in ex malesuada laoreet eget a nulla. Aliquam tristique et elit at consequat. In hac habitasse platea dictumst.
BEM: http://getbem.com/naming/
Constructors (and factory function): https://medium.com/javascript-scene/javascript-factory-functions-vs-constructor-functions-vs-classes-2f22ceddf33e
1-projects/Components-Constructors-Solution-master/
Table of Contents generated with DocToc
Topics:
- Naming Conventions
- BEM
- Constructors with ES6 class syntax
You will be building on your prior work from Components-BEM by adding a Tabs component.
The HTML and CSS for the Tabs component and instance are provided so that you may add your prior work around it. If you have not finished Components-BEM, ask you TA for the solution.
You may need to adjust some of the naming for the usuage of Box in the HTML provided if it's different in your implementation.
The Tabs component should be a grouping of links and associated items. Only one item is shown at a time, and each item is shown when its corresponding link is clicked. You should default to the first link and item upon page load.
You will also be doing a more complex query with querySelector and Data Attributes. It's a great challenge to try to work out on your own. If it's holding you back too much, you may ask your TA for the solution to that query.
Data Attributes: https://developer.mozilla.org/en-US/docs/Learn/HTML/Howto/Use_data_attributes
BEM: http://getbem.com/naming/
Constructors (and factory function): https://medium.com/javascript-scene/javascript-factory-functions-vs-constructor-functions-vs-classes-2f22ceddf33e
1-projects/Data-Structures-master/
Table of Contents generated with DocToc
Answer the following questions for each of the data structures you implemented as part of this project.
-
What is the runtime complexity of
pushusing a list? -
What is the runtime complexity of
pushusing a linked list? -
What is the runtime complexity of
popusing a list? -
What is the runtime complexity of
popusing a linked list? -
What is the runtime complexity of
lenusing a list? -
What is the runtime complexity of
lenusing a linked list?
-
What is the runtime complexity of
enqueueusing a list? -
What is the runtime complexity of
enqueueusing a linked list? -
What is the runtime complexity of
dequeueusing a list? -
What is the runtime complexity of
dequeueusing a linked list? -
What is the runtime complexity of
lenusing a list? -
What is the runtime complexity of
lenusing a linked list?
-
What is the runtime complexity of
ListNode.insert_after? -
What is the runtime complexity of
ListNode.insert_before? -
What is the runtime complexity of
ListNode.delete? -
What is the runtime complexity of
DoublyLinkedList.add_to_head? -
What is the runtime complexity of
DoublyLinkedList.remove_from_head? -
What is the runtime complexity of
DoublyLinkedList.add_to_tail? -
What is the runtime complexity of
DoublyLinkedList.remove_from_tail? -
What is the runtime complexity of
DoublyLinkedList.move_to_front? -
What is the runtime complexity of
DoublyLinkedList.move_to_end? -
What is the runtime complexity of
DoublyLinkedList.delete?a. Compare the runtime of the doubly linked list's
deletemethod with the worst-case runtime of the JSArray.splicemethod. Which method generally performs better?
-
What is the runtime complexity of
insert? -
What is the runtime complexity of
contains? -
What is the runtime complexity of
get_max? -
What is the runtime complexity of
for_each?
-
What is the runtime complexity of
_bubble_up? -
What is the runtime complexity of
_sift_down? -
What is the runtime complexity of
insert? -
What is the runtime complexity of
delete? -
What is the runtime complexity of
get_max?
Table of Contents generated with DocToc
-
Data Structures FAQ
-
Contents
-
General
- My imports aren't working, help!
- What are real-world use-cases for a Queue data structure?
- What are real-world use-cases for a Stack data structure?
- What are real-world use-cases for a Linked List data structure?
- How are Linked-Lists different than an Array?
- I've always been able to add as much as I want to an Array and take things out from the beginning, end, or anywhere else. It's never been a problem before, why are we bothering with all of this?
- What are real-world use-cases for a LRU Cache?
- What is the dictionary being used for in the LRU Cache?
- What are real-world use-cases for a Binary Search Tree data structure?
- How is the root element of a Binary Search Tree decided?
- What is the difference between Breadth First and Depth First?
- What is the difference between a Search and a Traversal?
-
General
-
Contents
Python can be tricky with how imports work and can vary from environment to environment. If you are having trouble, the easiest solution is to copy the file you want to import into the same folder as the file you want to import it into and use from file import class.
This is not a best practice for a real application, but it is acceptable for this exercise. Just remember that this may mean if you want to change or update your code, you will have to do it in multiple places.
Queues are used anywhere in which you want to work with data First in First Out (FIFO). Server requests, without any prioritization, are handled this way. We'll also use it to conduct a breadth first traversal and breadth first search.
Stacks are used when you want to work with data Last in First Out (LIFO or FILO). They're used in processor architecture, undo logic, and depth first searches and traversals.
Linked Lists can be used to create queues and stacks. They're also a key part of resolving collisions in hash tables, which we'll learn more about in a few weeks.
Both linked lists and arrays are linear data structures. An array is the most space efficient type of storage possible and has great time complexity for most operations. Logically, the array is linear in structure, and it is stored in a linear segment of memory. It is accessed by starting at the memory address of the pointer and counting forward the number of bits resulting from the index times the size of the data type. One weakness is the time complexity of operations that take data out of anywhere but the end and another is changing the size of the array.
A linked list is not as efficient for storage because each element requires a pointer to the next, and in a doubly-linked list, previous element. It is also more difficult to access the elements. Because there's no index, you must loop through the list to search for the item you want, which is O(n). However, a linked list does not require a contiguous block of memory. It has 0(1) to remove or add items anywhere in the list.
Generally speaking, it's usually best to use an array unless you expect to frequently add and remove items from anywhere other than the end. In that case, it's better to use a linked list.
I've always been able to add as much as I want to an Array and take things out from the beginning, end, or anywhere else. It's never been a problem before, why are we bothering with all of this?
We're looking under the hood! High level languages like Python abstract away most of the inner workings of everything we do. Most of the time this is a good thing and most of the time it doesn't matter. However, we're professional engineers and sometimes we need to solve problems where the details can have a major impact on success or failure. Think about your car. Do you know exactly how much weight you can put in it? Probably not, nor do you need to. But if you find yourself needing to put a load of bags of concrete in the trunk it suddenly becomes very important. As an engineer, you'll be expected to understand when the details do and do not matter.
An LRU cache is an efficient type of caching system that keeps recently used items and when the cache becomes full, pushes out the least recently used item in the cache. It can be used any time a subset of data is used frequently that needs to be pulled from a source with a long lookup time. For example, cacheing the most frequently accessed items from a database on a remote server.
We can't access items in a linked list directly because linked lists are not indexed. To see if an item is already in the cache, we'd need to loop through the cache at O(n). By also adding a dictionary to organize the nodes that are already present in memory, we index the linked list for a very small overhead cost.
A BST in the way that is being implemented for this project is a bit too simple to see any real-world use-cases. There are many (more complex) variants of BSTs that do see production use. One very notable variant is the B-tree, which is a self-balancing ordered variant of the BST. B-trees play a critical role in database and file system indexing. Other notable variants include the AVL tree, which is a self-balancing BST and the prefix tree, which is specialized for handling text.
The first element added to a BST is the root of the tree. However, doing it this way means that it's a very simple matter to end up with a lopsided BST. If we simply insert a monotonically ascending or descending sequence of values, then the tree would essentially flatten down to a linked list, and we'd lose all the benefits that a BST is supposed to confer. Self-balancing variants of the BST exist in order to alleviate this exact problem.
In depth first, we pick one path at each branch and keep going forward until we hit a dead end, then backtrack and take the first branch we find. In breadth first, we go by layers, one row deeper each time. This means that we jump around a bit.
A search and a traversal are processed exactly the same. The difference is that we stop a search when we find what we were looking for, or when all nodes have been visited without finding it. In a traversal, we always keep going until we've visited every node.
1-projects/Data-Structures-master/heap/
Table of Contents generated with DocToc
- Should have the methods
insert,delete,get_max,_bubble_up, and_sift_down.-
insertadds the input value into the heap; this method should ensure that the inserted value is in the correct spot in the heap -
deleteremoves and returns the 'topmost' value from the heap; this method needs to ensure that the heap property is maintained after the topmost element has been removed. -
get_maxreturns the maximum value in the heap in constant time. -
get_sizereturns the number of elements stored in the heap. -
_bubble_upmoves the element at the specified index "up" the heap by swapping it with its parent if the parent's value is less than the value at the specified index. -
_sift_downgrabs the indices of this element's children and determines which child has a larger value. If the larger child's value is larger than the parent's value, the child element is swapped with the parent.
-


A max heap is pretty useful, but what's even more useful is to have our heap be generic such that the user can define their own priority function and pass it to the heap to use.
Augment your heap implementation so that it exhibits this behavior. If no comparator function is passed in to the heap constructor, it should default to being a max heap. Also change the name of the get_max function to get_priority.
You can test your implementation against the tests in test_generic_heap.py. The test expects your augmented heap implementation lives in a file called generic_heap.py. Feel free to change the import statement to work with your file structure or copy/paste your implementation into a file with the expected name.
1-projects/Data-Structures-master/
Table of Contents generated with DocToc
Topics:
- Singly Linked Lists
- Queues and Stacks
- Doubly Linked Lists
- Binary Search Trees
- Related Code Challenge Problems
Stretch Goals:
- LRU Cache
- Heaps
- AVL Trees
- Module 1: Implement the Stack and Queue classes using built-in Python lists and the Node and LinkedList classes you created during the Module 1 Guided Project.
- Module 2: Implement the Doubly Linked List class
- Module 3: Implement the Binary Search Tree class
- Module 4: Implement traversal methods on Binary Search Trees
NOTE: The quickest and easiest way to reliably import a file in Python is to just copy and paste the file you want to import into the same directory as the file that wants to import. This obviously isn't considered best practice, but it is the most reliable way to do it across all platforms. If the import isn't working, feel free to try this method.
- Should have the methods:
push,pop, andlen.-
pushadds an item to the top of the stack. -
popremoves and returns the element at the top of the stack -
lenreturns the number of elements in the stack.
-
- Has the methods:
enqueue,dequeue, andlen.-
enqueueadds an element to the back of the queue. -
dequeueremoves and returns the element at the front of the queue. -
lenreturns the number of elements in the queue.
-
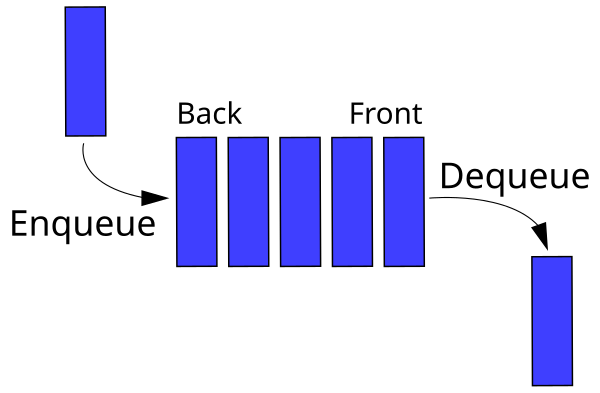
- The
ListNodeclass, which represents a single node in the doubly-linked list, has already been implemented for you. Inspect this code and try to understand what it is doing to the best of your ability. - The
DoublyLinkedListclass itself should have the methods:add_to_head,add_to_tail,remove_from_head,remove_from_tail,move_to_front,move_to_end,delete, andget_max.-
add_to_headreplaces the head of the list with a new value that is passed in. -
add_to_tailreplaces the tail of the list with a new value that is passed in. -
remove_from_headremoves the head node and returns the value stored in it. -
remove_from_tailremoves the tail node and returns the value stored in it. -
move_to_fronttakes a reference to a node in the list and moves it to the front of the list, shifting all other list nodes down. -
move_to_endtakes a reference to a node in the list and moves it to the end of the list, shifting all other list nodes up. -
deletetakes a reference to a node in the list and removes it from the list. The deleted node'spreviousandnextpointers should point to each afterwards. -
get_maxreturns the maximum value in the list.
-
- The
headproperty is a reference to the first node and thetailproperty is a reference to the last node.

- Should have the methods
insert,contains,get_max.-
insertadds the input value to the binary search tree, adhering to the rules of the ordering of elements in a binary search tree. -
containssearches the binary search tree for the input value, returning a boolean indicating whether the value exists in the tree or not. -
get_maxreturns the maximum value in the binary search tree. -
for_eachperforms a traversal of every node in the tree, executing the passed-in callback function on each tree node value. There is a myriad of ways to perform tree traversal; in this case any of them should work.
-

Once you've gotten the tests passing, it's time to analyze the runtime complexity of your get and set operations. There's a way to get both operations down to sub-linear time. In fact, we can get them each down to constant time by picking the right data structures to use.
Here are you some things to think about with regards to optimizing your implementation: If you opted to use a dictionary to work with key-value pairs, we know that dictionaries give us constant access time, which is great. It's cheap and efficient to fetch pairs. A problem arises though from the fact that dictionaries don't have any way of remembering the order in which key-value pairs are added. But we definitely need something to remember the order in which pairs are added. Can you think of some ways to get around this constraint?
An LRU (Least Recently Used) cache is an in-memory storage structure that adheres to the Least Recently Used caching strategy.
In essence, you can think of an LRU cache as a data structure that keeps track of the order in which elements (which take the form of key-value pairs) it holds are added and updated. The cache also has a max number of entries it can hold. This is important because once the cache is holding the max number of entries, if a new entry is to be inserted, another pre-existing entry needs to be evicted from the cache. Because the cache is using a least-recently used strategy, the oldest entry (the one that was added/updated the longest time ago) is removed to make space for the new entry.
So what operations will we need on our cache? We'll certainly need some sort of set operation to add key-value pairs to the cache. Newly-set pairs will get moved up the priority order such that every other pair in the cache is now one spot lower in the priority order that the cache maintains. The lowest-priority pair will get removed from the cache if the cache is already at its maximal capacity. Additionally, in the case that the key already exists in the cache, we simply want to overwrite the old value associated with the key with the newly-specified value.
We'll also need a get operation that fetches a value given a key. When a key-value pair is fetched from the cache, we'll go through the same priority-increase dance that also happens when a new pair is added to the cache.
Note that the only way for entries to be removed from the cache is when one needs to be evicted to make room for a new one. Thus, there is no explicit remove method.
Given the above spec, try to get a working implementation that passes the tests. What data structure(s) might be good candidates with which to build our cache on top of? Hint: Since our cache is going to be storing key-value pairs, we might want to use a structure that is adept at handling those.
An AVL tree (Georgy Adelson-Velsky and Landis' tree, named after the inventors) is a self-balancing binary search tree. In an AVL tree, the heights of the two child subtrees of any node differ by at most one; if at any time they differ by more than one, rebalancing is done to restore this property.
We define balance factor for each node as :
balanceFactor = height(left subtree) - height(right subtree)
The balance factor of any node of an AVL tree is in the integer range [-1,+1]. If after any modification in the tree, the balance factor becomes less than −1 or greater than +1, the subtree rooted at this node is unbalanced, and a rotation is needed.
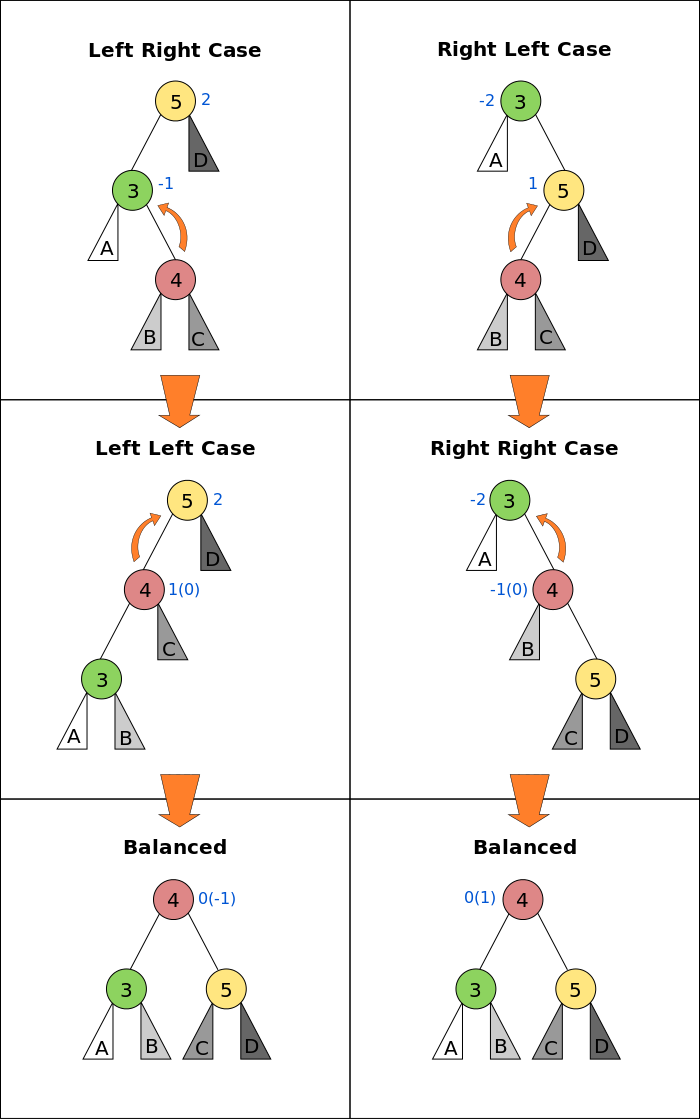
Implement an AVL Tree class that exhibits the aforementioned behavior. The tree's insert method should perform the same logic as what was implemented for the binary search tree, with the caveat that upon inserting a new element into the tree, it will then check to see if the tree needs to be rebalanced.
How does the time complexity of the AVL Tree's insertion method differ from the binary search tree's?
1-projects/DOM-JavaScript-mini-Solution-master/
1-projects/HTML-CSS-mini-Solution-master/
Table of Contents generated with DocToc
Topics:
- Box Model
- Flex Box
- BEM Naming Conventions
- Extra Credit: Media Queries
You will be turning the provided wireframe into a page. For your first implementation, use only box model rules. Half way through the alotted time, refactor what you have to use flexbox. Make your second solution on a second branch.
You're provided with an index.html file and a styles.css file to begin with, but you're welcome to restructure as you see fit. The mockups are also in the mockup folder for your reference. The full width version is the first you'll be implementing. The mid and small are for extra credit.
Box Model Study Guide

- Make your Box Model solution responsive to browser resizing using media queries. Media Query Min & Max Width Quick Reference


1-projects/Intro-Python-I-master/
Table of Contents generated with DocToc
-
FAQ
- Contents
-
Questions
- What are some things we can do to prepare for CS?
- Why is there such a debate between OOP and functional programming, and why should we care?
- In regard to the code challenge solution, why is the '+' operator being used to concatenate strings? I thought we were supposed to use the join() method in Python?
- How do you get out of the Python built-in
help? - Are there any helpful VS Code extensions that are recommend for using with Python?
- I'm on Windows; what command do I use to run Python?
- What version of Python do I need?
- Do I need to use pipenv?
- How do I get out of the Python REPL?
- What does "REPL" mean?
- I'm on a Mac and when I run Python it says I'm on version 2.7. Why?
- Does Python use tabs or spaces?
- How do I convert an iterator into a list?
- Does Python have hoisting?
- Does scoping work similar to other languages?
- Can you return a reference to a function from another function? Or store it in a variable?
- Can you use boolean shortcut assignments?
- Can you do anonymous functions?
- Is a dict like a JavaScript object?
- What are all those method names with double underscores around them?
- How do I get a value from a dict?
- When do we run pipenv shell?
- How do I get out of the pipenv shell?
- How do I install additional packages from pipenv?
- Is it possible to use system-wide packages from inside the virtual environment?
- Where are good Python docs?
- Which linter?
- Can you dynamically add new methods/properties to class through other functions? Or must all properties/methods be declared at once?
- Following this flow: 1) class Dog is created with attributes size and weight. 2) New instance called Snoopy of class Dog is created. 3) Class Dog gets the method bark() dynamically added to it. Question: will Snoopy now have access to bark() method?
- If a subclass inherits from two superclasses with a method of the same name, which method will the subclass use?
- How to handle multiple inheritance and why/when to do it in the first place?
- Why use tuples instead of lists?
- What's the difference between repr and str?
- How does
sys.argvwork? - How do I concatenate two arrays into a single array?
- What are some ways to learn a new language?
- Why test code frequently?
- Why isn't official documentation more helpful than Stack Overflow?
- During an interview, what do I do if I can't remember the exact syntax?
- What are some things we can do to prepare for CS?
- What are some ways to learn a new language?
- Why test code frequently?
- Why isn't official documentation more helpful than Stack Overflow?
- During an interview, what do I do if I can't remember the exact syntax?
- In regard to the code challenge solution, why is the '+' operator being used to concatenate strings? I thought we were supposed to use the join() method in Python?
- How do you get out of the Python built-in
help? - Are there any helpful VS Code extensions that are recommend for using with Python?
- I'm on Windows; what command do I use to run Python?
- What version of Python do I need?
- How do I get out of the Python REPL?
- What does "REPL" mean?
- I'm on a Mac and when I run Python it says I'm on version 2.7. Why?
- Does Python use tabs or spaces?
- Can you use boolean shortcut assignments?
- Can you do anonymous functions?
- What are all those method names with double underscores around them?
- Where are good Python docs?
- Which linter?
- What's the difference between repr and str?
- How does
sys.argvwork?
- Do I need to use pipenv?
- When do we run pipenv shell?
- How do I get out of the pipenv shell?
- How do I install additional packages from pipenv?
- Is it possible to use system-wide packages from inside the virtual environment?
- Why is there such a debate between OOP and functional programming, and why should we care?
- Following this flow: 1) class Dog is created with attributes size and weight. 2) New instance called Snoopy of class Dog is created. 3) Class Dog gets the method bark() dynamically added to it. Question: will Snoopy now have access to bark() method?
- Can you dynamically add new methods/properties to class through other functions? Or must all properties/methods be declared at once?
- If a subclass inherits from two superclasses with a method of the same name, which method will the subclass use?
- How to handle multiple inheritance and why/when to do it in the first place?
- Does Python have hoisting?
- Does scoping work similar to other languages?
- Can you return a reference to a function from another function? Or store it in a variable?
- Can you do anonymous functions?
- How do I convert an iterator into a list?
- Is a dict like a JavaScript object?
- How do I get a value from a dict?
- Why use tuples instead of lists?
- How do I concatenate two arrays into a single array?
- CS Wiki
- Polya's Problem Solving Techniques
- Solving Programming Problems
- CS Reading List
- How to Google effectively
- How to read specs and code
- Command line primer
- Coding style guidelines
There are a lot of programming paradigms and they all have their strengths and weaknesses when it comes to solving different types of problems.
People can be quite opinionated about their favorites, but it's important to remember that no one language or paradigm is the right tool for all jobs. And, additionally, that virtually all problems can be solved in any of the declarative or imperative paradigms. (Some might produce cleaner, more elegant code for a particular problem.)
Paradigms are the hardest thing to learn because you often have to take all the knowledge you have about solving a problem in another paradigm and throw it out the window. You have to learn new patterns and techniques to be effective.
But we encourage this kind of learning because most popular languages are to some degree multi-paradigm, and the more techniques you know from more paradigms, the more effective you are in that multi-paradigm langage.
In regard to the code challenge solution, why is the '+' operator being used to concatenate strings? I thought we were supposed to use the join() method in Python?
Using join() to join large numbers of strings is definitely faster in Python
than using the + operator to do it. The reason is that every time you join()
or use the + operator, a new string is created. So if you only have to
join() once, versus using + hundreds of times, you'll run faster.
That said, if you want to use the join() approach, you'll have to have all
your strings in a list, which uses more memory than just having the two or three
that you need at a time to use +. So there's a tradeoff.
Another tradeoff might be in readability. It might be easier to read the +
version. That's worth something.
Finally, if + is fast enough for this case, it might not be worth the time to
bother with making a list of strings to join().
Hit q for "quit".
It's a common command in Unix "pagers" (programs that show documents a page at a time).
If you're running in PowerShell or cmd, use:
py
If in bash, use python or python3.
You should have version 3.7 or higher. Test with:
python --versionYou should. Good Python devs know how.
Hit CTRL-D. This is the way End-Of-File is signified in Unix-likes.
Read, Evaluate, Print Loop.
It reads your input, evaluates it, and prints the result. And loops.
Macs come with version 2.7 by default. You'll need to install version 3.
And preferable use pipenv after that.
PEP 8 says four spaces.
Cast it:
list(range(5))produces:
[0, 1, 2, 3, 4]No.
Generally, and also not really. Variables are either global or function-local.
Since there are no declarations, there's no block-level scope.
It is similar to var in JavaScript.
Yes. Functions are first-class citizens.
Yes, you can. This is common in Perl and JavaScript, but it's not particularly idiomatic in Python.
x = SomethingFalsey or 5You can use lambda for simple functions:
adder = lambda x, y: x + y
adder(4, 5) # 9
do_some_math(4, 5, lambda x, y: y - x)Sort of.
The syntax is different, though. In Python you must use [] notation to access elements. And you must use " around the key names.
Those are function you typically don't need to use, but can override or call if you wish.
Most commonly used are:
-
__init__()is the constructor for objects -
__str__()returns a string representation of the object -
__repr__()returns a string representation of the object, for debugging
d = {
"a": 2,
"b": 3
}
print(d["a"])You don't use dot notation.
pipenv shell puts you into your work environment. When you're ready to work, or run the code, or install new dependencies, you should be in your pipenv shell.
Type exit.
pipenv install packagenameThis is not recommended.
- Official documentation tutorial and library reference.
The official docs might be hard to read at first, but you'll get used to them quickly
Pylint or Flake8. The latter seems to be a bit more popular.
Can you dynamically add new methods/properties to class through other functions? Or must all properties/methods be declared at once?
You can add them dynamically at runtime, but you have to add them to the class itself:
class Foo():
pass
f = Foo()
Foo.x = 12 # Dynamically add property to class
f.x == 12 # True!
def a_method(self):
print("Hi")
Foo.hi = a_method # Dynamically add method to class
f.hi() # Prints "Hi"This is not a common thing to see in Python, however.
Following this flow: 1) class Dog is created with attributes size and weight. 2) New instance called Snoopy of class Dog is created. 3) Class Dog gets the method bark() dynamically added to it. Question: will Snoopy now have access to bark() method?
Yes.
If a subclass inherits from two superclasses with a method of the same name, which method will the subclass use?
The answer to this is twofold:
-
Lots of devs and shops frown on multiple inheritance, so maybe just don't do it. (Discussion)
-
As for the order in which methods of the same name are resolved, check out the MRO Algorithm which is what Python uses.
class Base1:
pass
class Base2:
pass
class Derived(Base1, Base2): # Multiple inheritance
passSometimes multiple inheritance can lead to elegant solutions when a subclass needs attributes from multiple, otherwise-unrelated parent classes.
However, a lot of people find it's not worth the trouble) and opt for other solutions, like composition.
- Tuples are immutable. There's a school of thought that says bugs can be reduced if you make as many things immutable as you can.
- Tuples are faster than lists to access.
- Some tuples (containing primitive types), can be used as
dictkeys.
Generally speaking, __repr__ is the string a dev would want to see if they
dumped an object to the screen. __str__ is the string a user would want to see
if the object were print()ed.
The output of __repr__ should be valid Python code that can reproduce the
object.
class Goat:
def __init__(self, leg_count):
self.leg_count = leg_count
def __repr__(self):
return f'Goat(leg_count={self.leg_count})'
def __str__(self):
return f'a goat with {self.leg_count} legs'In action:
>>> g = Goat(4)
>>> str(g)
'a goat with 4 legs'
>>> g
Goat(leg_count=4)
>>> Goat(leg_count=4) # output of __repr__ makes a clone of that object!
Goat(leg_count=4)It's a list that holds command line arguments. This is a way for a user to run your program and specify different behavior from the command line.
Here's a small program that prints the command line arguments:
import sys
for i in range(len(sys.argv)):
print(f'Argument #{i} is: {sys.argv[i]}')and here's some output, assuming you named the script foo.py:
$ python foo.py
Argument #0 is: foo.py
$ python foo.py antelope buffalo
Argument #0 is: foo.py
Argument #1 is: antelope
Argument #2 is: buffalo
Note that the 0th element in the list is the name of the program.
Here's another program that prints up to whatever number the user specifies:
import sys
for i in range(int(sys.argv[1])):
print(i+1)Example runs:
$ python foo.py 2
1
2
$ python foo.py 4
1
2
3
4
Use extend().
a = [1, 2, 3]
b = [4, 5, 6]
a.extend(b)
print(a) # [ 1, 2, 3, 4, 5, 6 ]- Figure out how variables and functions work.
- Build small toy programs to test individual features.
- Build a larger project that exercises many features.
- Don't get frustrated! Treat the problem like a curiosity, a thing to be studied.
- Do small tutorials or code-alongs.
- Find docs you like.
- Learn the differences between this language and one you know.
- Learn this language's way of doing the things you know.
Things to look for in the new language:
- Collections (arrays, vectors, dictionaries)
- Data types
- Iterators
- Flow control (if, while, loops, etc)
- Functions
- etc.
It's often better to make progress in small increments than to write a bunch of stuff and test it in one go.
Also, it's easier to stay motivated if you spend 10 minutes getting a first version going, even if it's missing 99% of its features, and then starting to iterate on that.
Often official documentation is more geared toward being a concise reference. Stack Overflow is more of an example-based learning environment.
Sometimes you need to know the specific details. In those cases, you can dig into the spec, with all it's lawyerly language, and try to decipher what it is you have to do.
Other times, you just need a getting-started example, and Stack Overflow is great for that.
Both types of documentation have their purpose.
Just say so.
"I can't remember how to add an element to the end of the list in Python... is
it push()? In any case, we'll call the function here that does that."
(Turns out it's append() in Python, but being honest and describing what it is
your're trying to do will get you 99% of the way there in an interview.)
Table of Contents generated with DocToc
Note: This project spans two modules (modules 1 and 2). You should roughly try to finish the first half of the problems during module 1 and the second half of the problems during module 2.
It's time to learn a new language! Python!
Python is a popular, easy-to-use programming language that has significant traction in the field.
Remember the goal is learning to learn, so keep track of what works for you and what doesn't as you go through the process of exploring Python.
-
Try to relate things you already know in another language (e.g. what an array is) to the corresponding things in Python (e.g. a list) and how to use them.
-
Write a bunch of "toy programs" that demonstrate different key features of the language
-
Explore the standard library that's available for the language. Skim it briefly for now--the idea isn't to memorize everything but to file away generally what functionality is available.
-
Write a more substantial toy program that uses a variety of the features.
Again, keep track of what works for you. Try different things to see what works best for learning new languages.
- Installing Python 3
- JavaScript<->Python cheatsheet
- How to read Specs and Code
- Python 3 standard library
Make sure you have Python 3 installed. You can check this by running python3 --version in your terminal and ensuring that it returns a version string that is at least 3.6.5.
- Learn the basic syntax and structure of Python
- Implement a number of tiny Python programs that demonstrate Python syntax and language concepts.
Note: This project spans two modules (modules 1 and 2). You should roughly try to finish the first half of the problems during module 1 and the second half of the problems during module 2.
Each directory inside the src/ directory presents exercises revolving around a
particular concept in Python. Not all of these concepts are unique to Python (in
fact, most probably aren't). This means that you can leverage knowledge you've
obtained via exposure to other programming languages towards learning Python.
The suggested order for going through each of the directories is:
-
hello-- Hello world -
bignum-- Print some big numbers -
datatypes-- Experiment with type conversion -
modules-- Learn to import from modules -
printing-- Formatted print output -
lists-- Python's version of arrays -
tuples-- Immutable lists typically for heterogenous data -
slices-- Accessing parts of lists -
comprehensions-- List comprehensions -
dictionaries-- Dictionaries -
functions-- Functions -
args-- Arguments and Keyword Arguments -
scopes-- Global, Local, and Non-Local scope -
file_io-- Read and write from files -
cal-- Experiment with module imports and implement a text-based calendar -
classes-- Classes and objects
-
One of Python's main philosophical tenets is its emphasis on readability. To that end, the Python community has standardized around a style guide called PEP 8. Take a look at it and then go over the code you've written and make sure it adheres to what PEP 8 recommends. Alternatively, PEP 8 linters exist for most code editors (you can find instructions on installing a Python linter for VSCode here). Try installing one for your editor!
-
Rewrite code challenges you've solved before or projects you've implemented before in a different language in Python. Start getting in as much practice with the language as possible!
-
Write a program to determine if a number, given on the command line, is prime.
- How can you optimize this program?
- Implement The Sieve of Eratosthenes, one of the oldest algorithms known (ca. 200 BC).
1-projects/Intro-Python-II-master/
Table of Contents generated with DocToc
Refer to the FAQ in Intro-Python-I.
Remember that multiple variables can refer to the same object.
In the diagram below, there are only 2 Room objects, total. (There are more in the game, obviously, but in this diagram, there are 2.)
There are 5 variables. 3 of them point to the one Room object that is the foyer:
room['foyer']room['outside'].n_toplayer.location
The remaining 2 point to the one Room object that is the outside:
room['outside']room['foyer'].s_to
room['outside'] -> Room("Outside Cave Entrance")
^
|
room['foyer'].s_to
room['foyer'] -> Room("Foyer") <- player.location
^
|
room['outside'].n_to
If you want to move the player (who is in the foyer in the diagram) to another room, you just need to reassign that to any variable that points to that other room.
So if the player is in the foyer and types s to go south, we could set:
player.location = room['foyer'].s_to # we were in the foyer, then went south
and after that, the variable references would look like this, with player location pointing to the outside object:
player.location
|
v
room['outside'] -> Room("Outside Cave Entrance")
^
|
room['foyer'].s_to
room['foyer'] -> Room("Foyer")
^
|
room['outside'].n_to
Assigning doesn't copy the object. It just makes another reference to the same object.
Table of Contents generated with DocToc
Up to this point, you've gotten your feet wet by working on a bunch of small Python programs. In this module, we're going to continue to solidify your Python chops by implementing a full-featured project according to a provided specification.

-
Put your Python basics into practice by implementing a text adventure game
-
Practice writing code that conforms to a specification
- Create the input command parser in
adv.pywhich allows the program to receive player input and commands to move to rooms in the four cardinal directions. - Fill out Player and Room classes in
player.pyandroom.py
- Make rooms able to hold multiple items
- Make the player able to carry multiple items
- Add items to the game that the user can carry around
- Add
get [ITEM_NAME]anddrop [ITEM_NAME]commands to the parser
The /src directory contains the files adv.py, which is where the main logic for the game should live, room.py, which will contain the definition of the Room class, and player.py, which will contain the definition of the Player class.
-
Add a REPL parser to
adv.pythat accepts directional commands to move the player- After each move, the REPL should print the name and description of the player's current room
- Valid commands are
n,s,eandwwhich move the player North, South, East or West - The parser should print an error if the player tries to move where there is no room.
-
Put the Room class in
room.pybased on what you see inadv.py.-
The room should have
nameanddescriptionattributes. -
The room should also have
n_to,s_to,e_to, andw_toattributes which point to the room in that respective direction.
-
-
Put the Player class in
player.py.- Players should have a
nameandcurrent_roomattributes
- Players should have a
-
Create a file called
item.pyand add anItemclass in there.-
The item should have
nameanddescriptionattributes.- Hint: the name should be one word for ease in parsing later.
-
This will be the base class for specialized item types to be declared later.
-
-
Add the ability to add items to rooms.
-
The
Roomclass should be extended with alistthat holds theItems that are currently in that room. -
Add functionality to the main loop that prints out all the items that are visible to the player when they are in that room.
-
-
Add capability to add
Items to the player's inventory. The inventory can also be alistof items "in" the player, similar to howItems can be in aRoom. -
Add a new type of sentence the parser can understand: two words.
-
Until now, the parser could just understand one sentence form:
verbsuch as "n" or "q".
-
But now we want to add the form:
verbobjectsuch as "take coins" or "drop sword".
-
Split the entered command and see if it has 1 or 2 words in it to determine if it's the first or second form.
-
-
Implement support for the verb
getfollowed by anItemname. This will be used to pick upItems.-
If the user enters
getortakefollowed by anItemname, look at the contents of the currentRoomto see if the item is there.-
If it is there, remove it from the
Roomcontents, and add it to thePlayercontents. -
If it's not there, print an error message telling the user so.
-
Add an
on_takemethod toItem.-
Call this method when the
Itemis picked up by the player. -
on_takeshould print out "You have picked up [NAME]" when you pick up an item. -
The
Itemcan use this to run additional code when it is picked up.
-
-
Add an
on_dropmethod toItem. Implement it similar toon_take.
-
-
-
Implement support for the verb
dropfollowed by anItemname. This is the opposite ofget/take. -
Add the
iandinventorycommands that both show a list of items currently carried by the player.
In arbitrary order:
-
Add more rooms
-
Add scoring
-
Subclass items into treasures
-
Add a subclass to
ItemcalledLightSource.-
During world creation, add a
lampLightSourceto a convenientRoom. -
Override
on_dropinLightSourcethat tells the player "It's not wise to drop your source of light!" if the player drops it. (But still lets them drop it.) -
Add an attribute to
Roomcalledis_lightthat isTrueif theRoomis naturally illuminated, orFalseif aLightSourceis required to see what is in the room. -
Modify the main loop to test if there is light in the
Room(i.e. ifis_lightisTrueor there is aLightSourceitem in theRoom's contents or if there is aLightSourceitem in thePlayer's contents). -
If there is light in the room, display name, description, and contents as normal.
-
If there isn't, print out "It's pitch black!" instead.
-
Hint:
isinstancemight help you figure out if there's aLightSourceamong all the nearbyItems. -
Modify the
get/takecode to print "Good luck finding that in the dark!" if the user tries to pick up anItemin the dark.
-
-
Add methods to notify items when they are picked up or dropped
-
Add light and darkness to the game
-
Add more items to the game.
-
Add a way to win.
-
Add more to the parser.
-
Remember the last
Itemmentioned and substitute that if the user types "it" later, e.g.take sword drop it -
Add
Items with adjectives, like "rusty sword" and "silver sword".-
Modify the parser to handle commands like "take rusty sword" as well as "take sword".
- If the user is in a room that contains both the rusty sword and silver sword, and they type "take sword", the parser should say, "I don't know which you mean: rusty sword or silver sword."
-
-
-
Modify the code that calls
on_taketo check the return value. Ifon_takereturnsFalse, then don't continue picking up the object. (I.e. prevent the user from picking it up.)- This enables you to add logic to
on_taketo code things like "don't allow the user to pick up the dirt unless they're holding the shovel.
- This enables you to add logic to
-
Add monsters.
-
Add the
attackverb that allows you to specify a monster to attack. -
Add an
on_attackmethod to the monster class. -
Similar to the
on_takereturn value modification, above, haveon_attackprevent the attack from succeeding unless the user possesses asworditem. -
Come up with more stretch goals! The sky's the limit!
1-projects/Intro-to-C-master/
Table of Contents generated with DocToc
-
Intro to C FAQ
- Contents
-
Questions
runtests.sh: $'\r': command not foundorSyntax error: word unexpected (expecting "do")runtests.sh: 3: 56059 Segmentation fault: 11 $VALGRIND- Mac:
malformed objecterror when runningmake tests - Should I bother fixing compiler warnings?
- Can I accidentally destroy my computer running C code?
- Is a
structcomparable to something in Python or JS? Is it like a class? - Can you have default parameters in the structs?
- Why does unsigned char type accept a number when it's clearly referring to a character?
- When I pass an array as an argument to a function, when do I use pointer notation and when do I use array notation ?
- Why do functions tend to return pointers to structs, and not just copies of the struct?
- Why do we subtract '0' from a char to convert it from ASCII to a numeric value?
- When do I need a pointer to a pointer?
- Do other languages use pointers?
- What's the difference between "
int *x" and "int* x"? - What does the "implicit declaration of function" warning mean?
- What's the difference between
puts(),fprintf(), andprintf()? - Why does
025 == 21? - What is the "true dev workflow" in C?
- Does C have garbage collection?
- Why is C code faster than other languages?
- What is a segmentation fault and how do I stop it?
- What happens if my program exits but I forgot to
free()some memory I allocated? - What's the difference between a
floatand adouble, or between anintand along? - Can you use
+to concatenate two strings? - Are variables automatically initialized to zero when I declare them?
- What type should I use to hold numbers bigger than an
intcan hold? - What VS Code plugins are good for C development?
- What are some additional C resources?
- How do I get the debugger working?
- How do I print a pointer with
printf? - Does C have closures?
- If I look at an uninitialized variable, will the garbage in it ever be leftover data from another process?
- How many levels of indirection can you have with pointers?
int******? - What's the
incompatible integer to pointer conversionerror? - Are there any other ways besides
malloc()to store things on the heap? - For string literals like
"Hello", are those stored on the stack or heap? - Is the C stack like the stack data structure?
- Is the C heap like a binary heap data structure?
- What are
stdin,stdout, andstderr? - How do I know which header files to
#includefor any particular function? - When do I have to explicitly cast a type to another type?
- Is
realloc()the same as callingmalloc(), copying the data over, then callingfree()on the original pointer? - What happens if I
free()aNULLpointer? - What are bits, bytes, kilobytes, megabytes, and all that?
- In C, can we assume an
intis 32 bits? - What's the difference between
#includewith double quotes and#includewith angle brackets? - Should I declare a pointer to a thing, or just declare the thing?
- Is there a difference between
exit()andreturn? - Why does
strcmp()return0when strings match? Since0means "false" in C, that seems backwards. - What is "undefined behavior" in C?
- When you free a pointer, does it get set to
NULLautomatically? - How do I write preprocessor macros with
#define? - What is an
undefined symbollinker error? - How do I make my own header files and what do I put in them?
- How do I make my own Makefile?
- Why are there so many
printf()variants? How do I know which one to use? - Why is
main()always at the bottom of the file? - Why does
main()return0? What does the return value mean? - Do we have to have a
main()? Can there be more than one? - Can
main()returnvoid? What aboutmain()with no parameters? - Do we need a semicolon at the end of every line?
- Can a pointer point to more than one thing? What about to arrays and
structs? - If variables are stored in memory, where are pointers stored?
runtests.sh: $'\r': command not foundorSyntax error: word unexpected (expecting "do")runtests.sh: 56059 Segmentation fault: 11 $VALGRIND- Mac:
malformed objecterror when runningmake tests - What does the "implicit declaration of function" warning mean?
- What is a segmentation fault and how do I stop it?
- What's the
incompatible integer to pointer conversionerror? - What is an
undefined symbollinker error? - What is "undefined behavior" in C?
- Should I bother fixing compiler warnings?
- Can I accidentally destroy my computer running C code?
- Why do we subtract '0' from a char to convert it from ASCII to a numeric value?
- What's the difference between
puts(),fprintf(), andprintf()? - Why does
025 == 21? - What is the "true dev workflow" in C?
- Does C have garbage collection?
- Why is C code faster than other languages?
- Are variables automatically initialized to zero when I declare them?
- What VS Code plugins are good for C development?
- What are some additional C resources?
- How do I get the debugger working?
- Does C have closures?
- If I look at an uninitialized variable, will the garbage in it ever be leftover data from another process?
- What are
stdin,stdout, andstderr? - How do I know which header files to
#includefor any particular function? - What are bits, bytes, kilobytes, megabytes, and all that?
- What's the difference between
#includewith double quotes and#includewith angle brackets? - Why does
main()return0? What does the return value mean? - Is there a difference between
exit()andreturn? - What is "undefined behavior" in C?
- How do I write preprocessor macros with
#define? - How do I make my own header files and what do I put in them?
- How do I make my own Makefile?
- Why are there so many
printf()variants? How do I know which one to use? - Why is
main()always at the bottom of the file? - Do we have to have a
main()? Can there be more than one? - Can
main()returnvoid? What aboutmain()with no parameters? - Do we need a semicolon at the end of every line?
- Can you use
+to concatenate two strings? - For string literals like
"Hello", are those stored on the stack or heap? - Why does
strcmp()return0when strings match? Since0means "false" in C, that seems backwards.
- Is a
structcomparable to something in Python or JS? Is it like a class? - Can you have default parameters in the structs?
- Why do functions tend to return pointers to structs, and not just copies of the struct?
- Why does unsigned char type accept a number when it's clearly referring to a character?
- What's the difference between a
floatand adouble, or between anintand along? - What type should I use to hold numbers bigger than an
intcan hold? - When do I have to explicitly cast a type to another type?
- In C, can we assume an
intis 32 bits?
- When I pass an array as an argument to a function, when do I use pointer notation and when do I use array notation ?
- Why do functions tend to return pointers to structs, and not just copies of the struct?
- When do I need a pointer to a pointer?
- Do other languages use pointers?
- What's the difference between "
int *x" and "int* x"? - How do I print a pointer with
printf? - How many levels of indirection can you have with pointers?
int******? - What's the
incompatible integer to pointer conversionerror? - Should I declare a pointer to a thing, or just declare the thing?
- When you free a pointer, does it get set to
NULLautomatically? - Can a pointer pointer to more than one thing? What about to arrays and
structs? - If variables are stored in memory, where are pointers stored?
- What happens if my program exits but I forgot to
free()some memory I allocated? - Are there any other ways besides
malloc()to store things on the heap? - Is the C stack like the stack data structure?
- Is the C heap like a binary heap data structure?
- Is
realloc()the same as callingmalloc(), copying the data over, then callingfree()on the original pointer? - What happens if I
free()aNULLpointer? - When you free a pointer, does it get set to
NULLautomatically?
If you see this error:
Running unit tests:
: not foundtests.sh: 2: ./tests/runtests.sh:
./tests/runtests.sh: 4: ./tests/runtests.sh: Syntax error: word unexpected (expecting "do")You have two options:
-
Open the file
tests/runtests.shin VS Code in whatever subproject folder you're working in, e.g.fizzbuzz. Click on the lower right of the screen where it saysCRLF. ChooseLF. Save the file. Then the error should go away. -
You can do this from the command line with the
trcommand:
cd tests
cat runtests.sh | tr -d '\r' > runtests.tmp
mv runtests.tmp runtests.shThe root of the problem is a setting in git that causes all newlines (LF) to
be converted to carriage-return/newline (CRLF). The script runtests.sh is a
bash script that bash runs, and bash hates \r and pukes everywhere.
To cause git to not do newline conversion for future clones, run the following:
git config --global core.autocrlf false
This means you got a segfault in your program. See What is a segmentation fault and how do I stop it?
This is caused by an older version of the ar and ranlib packages being installed.
Sometimes these conflict with the versions installed with xcode.
If running MacPorts:
sudo port selfupdate
sudo port upgrade cctools
If running Brew:
sudo brew update
sudo brew upgrade gcc
YES!
In C, a warning is the compiler saying, "I can build that, and I will, but it's probably going to do something really messed up that you don't want."
There are only a few warnings you can safely ignore.
If you're absolutely sure the "unused variable" warning is OK, then you could ignore it. Or, better, add a line of code that silences the warning:
void foo(int a)
{
(void)a; // Do nothing, but at least the compiler will be quietNope! Not with a modern OS.
If you're running MS-DOS, then sure, you can do all kinds of things. I once accidentally blew away all my BIOS settings with a program I wrote and my computer wouldn't boot.
But Windows, Linux, macOS, BSD, or any other mainstream OS from this century all offer memory and resource protection that prevents you from changing memory you're not supposed to, or wiping out a disk you're not supposed to, etc.
The worst you'll see is a Segmentation fault message which means your program
tried to do something bad and the OS killed it.
It's like a class, except with only data (fields, properties) attached to it. There are no methods (functions) associated with it.
If you really want to pretend that you have methods on a struct, you can add
them as fields that are pointers to functions. The syntax is pretty obtuse,
and it's not a natural or idiomatic thing to do in C.
Example:
struct animal {
char *name;
// make_sound is a pointer to a function with no parameters that returns void
void (*make_sound)(void);
}
// Note how bleat() matches the signature for make_sound(), above
void bleat(void)
{
printf("Baaaahhhh!\n");
}
int main(void)
{
struct animal goat;
// C doesn't have the concept of a constructor, so we have to do it by hand:
goat.name = "goat";
goat.make_sound = bleat;
// Call the "method":
goat.make_sound(); // Baaaahhhh!
}No. The best you can do is have a helper function set the defaults.
void foo_default(struct foo *f)
{
f->a = 10; // Set defaults
f->b = 20;
f->c = 30;
}struct foo x;
foo_default(&x); // Set defaults
x.a = 99; // Override defaultWhen you declare a struct, you can also use an initializer to set the field
values:
struct foo x = { .a = 10, .b = 20, .c = 30 };Deep down, computers just deal in numbers (1s and 0s). They don't know what
a character is. We humans have come up with a system wherein a number
represents a certain character. For example, we've agreed that A is 65.
(For information on what number represents what character, look up more detail on ASCII encoding, or its modern superset UTF-8.)
With that in mind, C really only deals in numbers. Even when you put a character
in single quotes, it's still just a number. The only difference is in how we
interpret that number. That is, is it a value, like 65, or is it a character,
like A?
unsigned char c = 'A';
printf("%c\n", c); // Prints "A"
printf("%d\n", c); // Prints 65unsigned char c = 'A';
int x = c + 10;
printf("%d", x); // Prints 75, since 'A' == 65In C, whenever you have a character in single quotes like 'A', the compiler
treats it just like you'd put the number 65 there. (Or 66 for 'B', and so
on.)
The only difference between unsigned char and unsigned int is the number of
bytes that are used to represent the number. A char is onGe byte, and an int
is typically 4 bytes (but not always).
You can think of these additional bytes as analogous to adding more digits to your numbers. The more digits you have, the more range you can store. Two decimal digits only gets you from 0 to 99, but 8 digits gets you from 0 to 99999999. Similarly, one byte only gets you from 0 to 255, but 4 bytes gets you from 0 to 4,294,967,295.
If you never needed numbers larger than 255, you could use unsigned char for
all your variables! (But since modern computers are at least as fast with ints
as they are with chars, people just use ints.)
When I pass an array as an argument to a function, when do I use pointer notation and when do I use array notation ?
It's a little-known FunFact that C doesn't actually pass entire arrays to functions. It only passes pointers to the first element in that array.
int a[2000];
// "a" is a pointer to the first element in the array.
// It's the same as &(a[0]).
foo(a);So when you declare your function, you can do any of these:
void foo(int *a)void foo(int a[])void foo(int a[1])void foo(int a[2000])void foo(int a[999999999])and it treats them all as if you'd used:
void foo(int *a)There's a difference if you want to use multidimensional arrays. You must declare all the dimensions except the first one, which is optional. The compiler needs to know the other dimensions so it can do its array indexing computations correctly.
int foo(int x[][30]) // 30 wide
{
return x[2][4];
}
int main(void)
{
int a[10][30]; // 30 wide
foo(a);This only applies for multidimensional arrays. For 1-dimensional arrays, the rule still applies; you still need to specify all dimensions except the first one... but since there is only one, you never need to specify it.
It's possible to do this:
struct foo my_func(void)
{
struct foo f;
f.x = 10;
return f; // Return a copy of f
}as opposed to:
struct foo *my_func(void)
{
struct foo *p = malloc(sizeof(struct foo));
p->x = 10;
return p; // Return a copy of p
}But in C, it's more idiomatic to return a copy of the pointer to the memory
allocated than it is to return a copy of the struct itself.
Part of the reason for this is that it takes time to copy data. A struct can
be very large depending on how many fields it has in it, but your average
pointer is only 8 bytes.
Since every time you return a thing, a copy of that thing gets made, it is
faster to copy a pointer than it is to copy a struct of any non-trivial size.
Finally, note that this variant always invokes undefined behavior and should never be used:
struct foo *my_func(void)
{
struct foo f;
f.x = 10;
return &f; // Return a copy of a pointer to f
}The reason is because f vaporizes as soon as the function returns (since it's
just a local variable), so any pointers to it are invalid.
The code typically looks like this:
char c = '2'; // ASCII '2'
int v = c - '0'; // Convert into numeric value 2
printf("%d\n", v); // prints decimal 2Remember that in C, a char is like a small int, and when you have a
character in single quotes like '2', C replaces that with the
ASCII value of that character.
In the case of our example, the ASCII value of '2' is 50. And we want to
convert that to the numeric value 2. So we clearly have to subtract 48 from
it, since 50 - 48 = 2. But why the '0', then?
Here's part of the ASCII table, just the numbers:
| Character | ASCII value |
|---|---|
'0' |
48 |
'1' |
49 |
'2' |
50 |
'3' |
51 |
'4' |
52 |
'5' |
53 |
'6' |
54 |
'7' |
55 |
'8' |
56 |
'9' |
57 |
It's no coincidence it's done this way. Turns out that if you subtract 48 from
any ASCII character that is a digit, you'll end up with the numeric value of
that ASCII character.
Example: '7' is value 55 (from the table), compute 55 - 48 and you get
7.
And since '0' is 48, it's become idiomatic in C to convert ASCII digits to
values by subtracting '0' from them.
There are a few reasons you might need one, but the most common is when you pass a pointer to a function, and the function needs to modify the pointer.
Let's take a step back and see when you just need to use a pointer.
void foo(int a)
{
a = 12;
}
int main(void)
{
int x = 30;
printf("%d\n", x); // prints 30
foo(x);
printf("%d\n", x); // prints 30 again--not 12! Why?
}In the above example, foo() wants to modify the value of x back in main.
But, alas, it can only modify the value of a. When you call a function, all
arguments get copied into their respective parameters. a is merely a copy
of x, so modifying a has no effect on x.
What if we want to modify x from foo(), though? This is where we have to use
a pointer.
void foo(int *a)
{
*a = 12; // Set the thing `a` points at to 12
}
int main(void)
{
int x = 30;
printf("%d\n", x); // prints 30
foo(&x);
printf("%d\n", x); // prints 12!
}In this example, foo() gets a copy of a pointer to x. (Everything gets
copied into the parameters when you make a call, even pointers.)
Then it changes the thing the pointer points to to 12. That pointer was
pointing to x back in main, so it changes x's value to 12.
Great!
So what about pointers to pointers? It's the same idea. Let's do a broken example:
void alloc_ints(int *p, int count)
{
p = malloc(sizeof(int) * count); // Allocate space for ints
}
int main(void)
{
int *q = NULL;
alloc_ints(q, 10); // Alloc space for 10 ints
printf("%p\n", q); // Prints NULL still!!
q[2] = 10; // UNDEFINED BEHAVIOR, CRASH?
}What happened?
When we call alloc_ints(), a copy of q is made in p. We then assign into
p with the malloc(), but since p is just a copy of q, q is unaffected.
It's just like our first version of foo(), above.
Solution? We need to pass a pointer to q to alloc_ints() so that
alloc_ints() can modify the value of q.
But q is already a pointer! It's an int *! So when we take the address-of it
(AKA get a pointer to it), we'll end up with a pointer to a pointer, or an int **!
void alloc_ints(int **p, int count)
{
// Allocate space for ints, store the result in the thing that
// `p` points to, namely `q`:
*p = malloc(sizeof(int) * count);
}
int main(void)
{
int *q = NULL;
alloc_ints(&q, 10); // Alloc space for 10 ints
printf("%p\n", q); // Prints some big number, good!
q[2] = 10; // works!
}Success!
Most all of them do, but some are more explicit about it than others. In languages like Go, C, C++, and Rust, you have to use the proper operators when using pointers and references.
But languages like JavaScript and Python do a lot of that stuff behind your back. Take this Python example:
class Foo:
def __init__(self, x):
self.x = x
def bar(a):
a.x = 12 # Sets `f.x` to 12--why?
a = None # Does NOT destroy `f`--why not?
f = Foo(2)
print(f.x) # Prints 2
bar(f)
print(f.x) # Prints 12--why?Let's look what happened there. We made a new object f, and we passed that
object to function bar(), which modified its x property.
After enough time with Python, we learn that it passes objects by reference.
This is another way of saying it's using pointers behind your back. Behind the
scenes in Python, a is a pointer to f.
That's why when we modify a.x, it actually modifies f.x.
And it's also why when we set a to None, it doesn't change f at all. a
is just a pointer to f, not f itself.
Let's look at the C version of that Python program. This works exactly the same way:
#include <stdio.h>
struct foo {
int x;
};
void bar(struct foo *a)
{
a->x = 12; // Sets f.x to 12--why?
a = NULL; // Does NOT destroy `f`--why not?
}
int main(void)
{
struct foo f = { 2 };
printf("%d\n", f.x); // Prints 2
bar(&f);
printf("%d\n", f.x); // Prints 12--why?
}a is a pointer to f. So we when do a->x, we're saying "set the x
property on the thing that a points to".
And when we set a to NULL, it's just modifying a, not the thing that a
points to (namely f).
Syntactically, nothing. They're equivalent.
That said, the recommendation is that you use the form int *x.
Here's why. These two lines are equivalent:
int* x, y;int *x, y;In both of them, x is type int*, and y is type int. But by putting the
asterisk right next to the int, it makes it look like both x and y are of
type int*, when in fact only x is.
If we reverse the order of x and y, we must necessarily move the asterisk
with x:
int y, *x; // Also equivalent to the previous two examplesIt's idiomatic to keep the asterisk tucked up next to the variable that's the pointer.
This is the compiler saying "Hey, you're calling a function but I haven't seen a declaration for that function yet." Basically you're calling a function before you've declared it.
If you're calling a library function like printf() or a syscall like stat(),
the most common cause of this warning is failure to #include the header file
associated with that function. Check the man page for exactly which.
But what if you're getting the error on one of your own functions? Again, it means you're calling that function before you've declared it.
But what does declared mean?
A declaration can either be a function definition, or a function prototype.
Let's look at a broken example:
#include <stdio.h>
int main(void)
{
foo(); // Implicit declaration warning!!
}
void foo(void)
{
printf("Foo!\n");
}In that example, main() calls foo(), but the compiler hasn't seen a
declaration of foo() yet. We can fix it by defining foo() before main():
#include <stdio.h>
// Just moved foo()'s definition before main(), that's all
void foo(void)
{
printf("Foo!\n");
}
int main(void)
{
foo(); // No problem!
}You can also use a function prototype to declare a function before it is used, like so:
#include <stdio.h>
void foo(void); // This is the prototype! It's a declaration of foo().
int main(void)
{
foo(); // No problem
}
void foo(void) // This is the definition of foo()
{
printf("Foo!\n");
}Prototypes for functions that are callable from other source files typically
go in header files, and then those other source files #include them.
For functions that aren't used outside the current .c file (e.g. little helper
functions that no other file will even need to call), those usually are either
defined at the top of the file before their first call. If that's inconvenient,
a prototype can be placed at the top of the .c file, instead.
puts() simply outputs a string. It does no formatting of variables. Its only
argument is a single string. Additionally, it prints a newline at the end for
you.
// This prints "Hello, world %d!" and then a newline:
puts("Hello, world %d!");printf() does formatted output of variables, and strings as well. It's a
superset of puts(), in that way.
int x = 12;
// This prints "Hello, world 12!\n":
printf("Hello, world %d!\n", x);fprintf() is just like printf(), except it allows you to print to an open file.
FILE *fp = fopen("foo.txt", "w");
int x = 12;
// This writes "Hello, world 12!\n" to the file "foo.txt":
fprintf(fp, "Hello, world %d!\n", x);Incidentally, there's already a file open for you called stdout (standard
output) which normally prints to the screen. These two lines are equivalent:
printf("Hello, world!\n");
fprintf(stdout, "Hello, world!\n"); // Same thing!There's another already-opened file called stderr (standard error) that is
typically used to print error messages. Example:
if (argc != 2) {
fprintf(stderr, "You must specify a command line argument!\n");
exit(1);
}In C, any time you have a plain leading 0 on front of a number, the compiler
thinks your number is base-8 or octal.
Converting 025 to decimal can be done like so:
2*8 + 5*1 = 16 + 5 = 21
Octal is rarely used in practice, and it's common for new C programmers to put
0 in front of a number in error.
One of the last common places to see octal numbers is in Unix file permissions.
There is none.
Initially, it was in a Unix-like system probably using Makefiles to build the software. This is the system we use at Lambda.
And modern C development under Unix still follows this pattern, except maybe using autotools or CMake.
But dev for specific platforms like Windows probably happens in Visual
Studio instead of using
make and the rest of it.
Nope!
When it comes to freeing up memory that is no longer needed by the program, there are basically two schools of thought:
- Have the programmer manually manage that memory by explicitly allocating and
freeing it. (C's
malloc()andfree()functions.) - Have the runtime automatically manage all that for you. (Garbage collection, automatic reference counting, etc.)
C is too low-level to automatically manage memory usage for you.
One exception is that C automatically allocates and frees local variables just
like other languages you're used to. You don't have to explicitly call free()
for locals (and it's an error to do so). You must call free for any and all
pointers to data that you got back from malloc() when you're done with them.
Also, when a program exits, all memory associated with it is freed by the OS,
whether locals or malloc()d data.
The big thing is interpreted versus compiled.
Python and JavaScript are interpreted languages, which means another program
runs your program. It's software running software. So you run python code with
the python program and JavaScript code with node, for example.
So in that case, we have the CPU running python, and the Python running your
Python program. Python is the middleman, and that takes execution time.
C is a compiled language. The compiler takes your C code, and produces machine code. The CPU runs it directly. No middleman, so it's faster.
But other languages are compiled (like Go, Swift, Rust, C++, and so on). Why is C faster than them, typically?
It's because C is a no-frills, minimalist language. The code you write in C is actually quite close to the machine code that gets produced by the compiler, so it doesn't have to do a lot of things behind your back.
Additionally, people have been working on optimizing the output from C compilers for over 45 years. That's a big head start over other languages.
It means you've accessed some memory you weren't supposed to. The OS killed your process to prevent it from doing so.
The trick is to find the line that's causing the problem. If you get a debugger installed, this can really help.
In lieu of that, use well-positioned printf calls to figure out what the last
thing your program does before it crashes.
The bug almost certainly has to do with pointers or arrays (which are just pointers behind syntactic sugar).
Maybe you're accessing a NULL pointer, or an array out of bounds, or modifying
something you're not allowed to modify.
All memory associated with a process is freed when the program exits, even if
you forgot to free() it.
It's considered shoddy programming to not free() all the things you
malloc()d, though. The OS will free it, but it's bad style to rely on that.
It's all about the range of numbers you want to be able to store.
double can hold a more precise number than a float.
A float might only be precise up to 3.14159, but a double could hold
3.1416925358979, for example.
Likewise, an int might only be able to hold numbers up to 2 billion or so, but
a long could hold much larger numbers.
Use as little as you need. If a float or int can do the job, use them. If
you need more precision or larger numbers, step up to the next larger type.
No.
The reason is that strings are represented as char* types, and adding two
char*s together is not a defined operation in C.
Use the strcat() function in <string.h> to concatenate one string onto
another.
No.
Always explicitly initialize your variables, whether they be pointers or regular types. If you don't, random garbage will be in them when you use them.
Exception: local variable declared with
staticstorage class (this concept is out of scope for Lambda) and global variables get initialized to zero automatically. But it's still good form to explicitly initialize them.
If you don't need negative numbers, try unsigned int.
If that's not enough, try long.
If that's not big enough, try long long (yes, that's a real thing).
If those aren't enough, try unsigned long long.
If you just need big numbers, but not a lot of precision, you can use double or long double.
If you need big numbers and a lot of precision and none of the above are big enough, check out the GNU Multiple Precision library. It does arbitrary precision arithmetic to as much precision as you have RAM.
"C/C++ IntelliSense, debugging, and code browsing" by Microsoft is a good one.
A great C book is The C Programming Language Second Edition, by Kernighan [the "g" is silent] and Ritchie. It's affectionately referred to simply as K&R2.
A less great book that is free online is Beej's Guide to C Programming.
A good, comprehensive FAQ is the comp.lang.c FAQ.
There's no "one true source" of C info online, unfortunately.
Googling printf example, for example, will get you good results.
Googling man printf will bring up the man page for printf.
The commonly-used debugger is called gdb (GNU Debugger).
Lambda's own Brian Ruff got it working on the Mac, and made a video covering it.
These instructions are reported good for WSL on Windows.
The CS Wiki page might help, but it's slightly outdated since VS Code is in heavy development.
This video is reported good, as well.
If you're not seeing program output in the Output tab, try adding this to your
launch.json:
"externalConsole": trueWe recommend Googling for vscode gdb setup macos, substituting whatever
platform you're on for macos and setting the search date range to be recent.
Use the %p format specifier. This will print the value of the pointer (i.e.
the memory address), not what it's pointing to (i.e. the value stored at that
memory address.)
In practice, pointers are rarely printed except for debugging.
No, not in the way that you're used to from higher-level languages. What C does have that essentially acts as a poor man's closure is function pointers. These are literally what their name implies: pointers to functions.
The standard library implementation of the quicksort sorting algorithm provides a good example of this. It's function signature is
void qsort(void *base, size_t nitems, size_t size, int (*compare)(const void *, const void *))
The parameter to notice is the int (*compare)(const void *, const void *). This is a function pointer, mainly denoted by the asterisk in front of the function name all wrapped in parentheses and followed by another set of parentheses containing a parameter signature.
This signature is saying that the qsort function, in addition to the other parameters it receives, also receives a pointer to a function that receives two const void *s and returns an int.
Function pointers are used to fulfill the same use case as closures. They can be used to pass some dynamic logic into another function. In the case of qsort, the function pointer points to a function that specifies how the comparison for the sorting should be done.
If I look at an uninitialized variable, will the garbage in it ever be leftover data from another process?
Not on a modern OS. It would be a security risk, so the OS makes sure this never happens.
It's effectively unlimited. But the more you have, the less readable your code is.
In real life:
- 99.8% (roughly) of pointer usage is single indirection, like
int*. - 1.5% (roughly) is double indirection, like
char**. - And the remaining 0.5% is the rest of it.
This means you have a type mismatch in your assignment.
One side of the = has pointer type, and the other side has integer type.
If you have a pointer in your assignment, both side of the = must be the same
pointer type.
Maybe you meant to take the address of the right hand side? Or dereference the right hand side?
Short answer: no.
(We're assuming that by malloc() we mean malloc(), calloc(), and
realloc().)
The longer answer is that you can make a syscall and request more RAM from the
operating system. In practice, this is very rare; people just call malloc().
In Unix, that syscall is brk() (or sbrk()). The behavior of this call is a bit strange no
Neither.
Consider it to be stored in such a way that it is perpetually accessible from the entire program for the entire run and is never freed. So sort of like the heap.
This code is just fine:
char *hello(void)
{
char *s = "hello!";
return s;
}s is a local variable that is set to point to the string "hello!", and s
is deallocated as soon as the function returns. But the data s points to
(namely the "hello!") persists for the entire life of the program and is never
freed.
It's not actually on the heap, though. The C memory map looks like this, typically:
+--------------------+
| Stack |
| | |
| v |
+- - - - - - - - - - +
| |
| |
| |
+- - - - - - - - - - +
| ^ |
| | |
| Heap |
+--------------------+
| Uninitialized data |
+--------------------+
| Initialized data |
| (Read-Write) |
+--------------------+
| Initialized data |
| (Read-Only) |
+--------------------+
| Program code |
+--------------------+
Constant strings are found in the read-only initialized data section of memory.
If you try to write to one, your program will likely crash:
char *s = "Hello!";
*s = 'B'; // segfault!Yup! It's used by C to allocate space for local variables when you call functions.
When you return from a function, all those local variables are popped off the stack and thrown away. (Which is why local variables only last as long as the function!)
No--it's just a name collision.
Just assume the heap is a big, contiguous chunk of memory. It can be used for
whatever, but in C, it is typically managed by malloc() and free() so that
we don't have to worry about it.
These are the three files that are automatically opened for a process when it is first created.
| Stream | File Name | Device |
|---|---|---|
| Standard Input | stdin |
Keyboard |
| Standard Output | stdout |
Screen |
| Standard Error | stderr |
Screen |
stderr is typically used specifically for error messages, even though it goes
to the same place as stdout. (The idea is that you can redirect all normal
output to one place, and all error output to another place. Or suppress normal
output while allowing error output.)
Check the man page for the function in question. It'll show it in the Synopsis section.
Example for printf():
SYNOPSIS
#include <stdio.h>int printf(const char * restrict format, ...);
Note that if you type man on the command line for a particular function, you
might a manual page for another command that isn't the C function. In that case,
you have to specify the proper section of the manual for the function.
Try section 3 for library functions, and section 2 for syscalls.
Example looking for printf() in section 3:
man 3 printfAnd section 2 for the mkdir() syscall:
man 2 mkdirBarely ever.
C is pretty good about conversions, and you should be able to build almost everything without casting.
What if you need constant types?
// Print a double:
// (Floating point constants are double by default.)
printf("%lf\n", 3.14);
// Print a float:
printf("%f\n", 3.14f);
// Print a long double
printf("%Lf\n", 3.14L);
// Print a long integer:
printf("%ld\n", 99L);
// Print a long long integer:
printf("%lld\n", 99LL);
// Produce a floating result of a calculation by making sure at least
// one of the operands is a float:
float sort_of_pi = 22.0f / 7;
double double_pi = 22.0 / 7;What if you need to cast a void pointer?
void foo(void *p)
{
// convert p to a char*
char *q = p;
// Don't need to cast return value from malloc
int *z = malloc(sizeof(int) * 100);Some exceptions:
void foo(int a)
{
// Cast an unused variable to type void to suppress compiler warnings:
(void)a;
// If the compiler is warning about an unused return value:
(void)printf("Hello, world!\n");
// Cast to a char pointer to iterate over bytes of an object:
// (C99 6.3.2.3 paragraph 7 allows this.)
float f = 3.14;
unsigned char *c = (unsigned char *)&f;
for (unsigned i = 0; i < sizeof f; i++) {
printf("%02x ", c[i]);
}
printf("\n");Is realloc() the same as calling malloc(), copying the data over, then calling free() on the original pointer?
Effectively, yes, it's the same. Practically, you should use realloc().
realloc() might be more efficient because in some cases it might not have to
copy.
If you grow the space and realloc() knows there's extra unused memory right
after the existing space, it will simply tack that addition space onto the end
of the memory region and not bother moving the data.
Also, if you shrink the space, realloc() will likely not copy the data. It'll
just truncate it.
Nothing. It's a no-op.
Basically, inside the library code for free(), there's something that looks
like this:
void free(void *ptr)
{
if (ptr == NULL) {
return;
}According to the C99 spec section 7.20.3.2p2:
The
freefunction causes the space pointed to byptrto be deallocated, that is, made available for further allocation. Ifptris a null pointer, no action occurs. Otherwise, if the argument does not match a pointer earlier returned by thecalloc,malloc, orreallocfunction, or if the space has been deallocated by a call tofreeorrealloc, the behavior is undefined.
A bit is a single 1 or 0.
That's all the numbers it can represent.
A nibble is 4 bits. It can represent numbers from 0b0000 to 0b1111 (binary
numbers), which is equivalen to 0 to 15 in decimal.
A byte is 8 bits. It can represent numbers from 0b00000000 to 0b11111111,
or 0 to 255 decimal. (Historically, bytes could be other numbers of bits,
but on all modern systems, it's always 8 bits. Octet is another term for a
number that is specifically 8 bits long.)
A kilobyte is 1024 bytes. (1024 is 210.)
A megabyte is 1024 kilobytes (1,048,576 bytes).
A gigabyte is 1024 megabytes (1,073,741,824 bytes).
A terabyte is 1024 gigabytes (1,099,511,627,776 bytes).
A petabyte is 1024 terabytes (1,125,899,906,842,624 bytes).
If you're used to SI unit prefixes, you might be wondering why in computers kilo means 1024 instead of 1000 like it normally does. In short, it's for historic reasons. 1024 was close enough, so computer programmers adopted the SI prefixes, albeit with a slightly different value.
And that gets confusing. When I say kilobyte, do I mean 1000 bytes or 1024 bytes?
In almost every single case, kilobyte means 1024 bytes. (Hard drive and SSD sizes are sometimes an exception to this rule.)
To remove the ambiguity, you can use a binary prefix, where you'd say kibibyte if you specifically meant 1024 bytes.
That said, in conversation, if someone says kilobyte, odds are extremely high they mean 1024 bytes, not 1000 bytes. kibibyte is uncommonly used in conversation.
No.
You can assume an int is at least 16 bits (2 bytes).
There is only one type that has a guaranteed size: sizeof(char) will always be
1 byte. (Same for unsigned char and signed char.)
Never write code that hardcodes or assumes the size of anything other than
char. Always use sizeof to get the size.
There's a great Wikipedia article that lists the minimum sizes of the types. If you want your code to be portable to other compilers and systems, choose a type with a minimum size that works for the numbers you need to hold.
In general, use double quotes for your own header files, and angle brackets for
built-in system header files like <stdio.h>.
When you #include "foo.h", it looks for foo.h in the same directory as the
source file doing the including.
You can also use relative paths, and it'll look relative to the including source file:
#include "../bar.h"
#include "somedir/baz.h"When you #include <frotz.h>, it looks in the system include directories for
the header file. This is where all the built-in header files are installed. On
Unix machines, this tends to be the /usr/include directory, but it depends on
the OS and compiler.
It depends on if you want a thing or not, or if you just want to point to another, already-existing thing.
If there is not an already-existing thing, then making a pointer doesn't make sense. There's no existing thing for it to point to.
This does not declare an int:
int *p;There's no int there. We have an int pointer, but it's uninitialized, so it
points to garbage and can't be used.
So the question to ask is, "Do I already have an existing thing that I can point to? And if so, do I want to point to it?" If the answer to either is "no", then don't use a pointer.
Example:
int a = 12; // here's an existing thingSo the answer to the first part of the question is yes. And do we want a pointer to it? Sure, why not?
int *p = &a; // and there's a pointer to itIf you're in the main() function, then no.
If you're in any other function, then yes.
exit() always exits the running process, no matter where you call it from.
If you're in main(), return also exits the running process.
If you're in any other function, return just returns from that function.
strcmp() returns the difference between two strings. If the strings are the
same, there is zero difference, so it returns zero.
This gives strcmp() a little extra power over just returning a boolean
true/false value.
For example, if you run this:
strcmp("Antelope", "Buffalo");it will return less-than zero because "Antelope" is alphabetically less than "Buffalo".
So not only can it tell you if the strings are the same, it can tell you their
relative sort order. And that means you can pass it in as the comparator
function to the library built-in qsort() function.
There are a number of things you're allowed to do in C where the compiler is allowed to produce code that can have any indeterminate effect. It could work, it could crash, it could sort of work, it could crash sometimes and not others, it could crash on some machines and not others.
When you write code that does that, we say the code has undefined behavior.
Wikipedia has a number of practical examples, and if you look in the C99 Language Specification, Annex J.2 you can get a list of all the things you can do that cause undefined behavior.
At Lambda, the most common things you can do to get UB is using bad pointer references.
- Accessing memory you've already
free()d. - Freeing memory more than once.
- Accessing an array off the end of its bounds.
- Dereferencing a pointer that points to garbage.
- Dereferencing a
NULLpointer. - Returning a pointer to a local variable and dereferencing that.
GCC with -Wall -Wextra should warn on a lot of these. This is why it's
really important to fix all those warnings.
No.
Furthermore, free() can't do that even if it wanted to.
int *p = malloc(100 * sizeof(int));
free(p);When we call free(), it gets a copy of the pointer we pass in. (All
functions always get copies of all arguments you pass in.) As such,
free() could set its copy of p to NULL, but that doesn't affect our
original p.
p remains whatever value was in it until we set it to something else.
int *p = malloc(100 * sizeof(int));
free(p);
p = NULL; // NOW p is NULL(Note that it's undefined behavior to dereference a pointer after
you've free()d it. But it's still OK to change that pointer's value.)
You've probably already seen simple cases of #define like this:
#define antelopes 10
int main(void)
{
printf("Antelopes: %d\n", antelopes); // prints 10What's actually happening here is the preprocessor runs through the code before the compiler ever sees it. It manipulates the above code to read:
int main(void)
{
printf("Antelopes: %d\n", 10); // prints 10and then hands it off to the compiler. The compiler itself knows nothing about
#define.
These #define macros can also accept parameters that make them behave like
functions in a way.
Example:
#define square(x) x * x // Not quite Right. See below.
int main(void)
{
printf("9 squared is %d\n", square(9));Then the preprocessor generates this code for the compiler:
int main(void)
{
printf("9 squared is %d\n", 9 * 9);It just substitutes the parameters in as-is.
Another example:
#define square(x) x * x // Not quite Right. See below.
int main(void)
{
printf("3 + 2 squared is %d\n", square(3 + 2));Then the preprocessor generates this code for the compiler, merely substituting in exactly what the dev entered as an argument:
int main(void)
{
printf("3 + 2 squared is %d\n", 3 + 2 * 3 + 2);Except that prints 11, when it should print 25 (3 + 2 is 5, and 5 squared is
25)! We have a bug!
Of course, this has to do with the order of operations. We wrote:
3 + 2 * 3 + 2when what we really wanted was:
(3 + 2) * (3 + 2)For this reason, you should always put extra parentheses around the macro body, and around every parameter in the body:
#define square(x) ((x) * (x))And now the expansion of our line will be:
((3 + 2) * (3 + 2))That will work in all expected cases.
This happens when you've called a function, and the linker can't find it in any of the source files or libraries that you're using.
Do you have a warning about an implicit function declaration from the compiler before this error? If so, fix that first.
If not, it could be that you haven't specified all the source files needed on
the command line. If you have two sources one.c and two.c, and one calls
functions that are in the other, then you have to pass both into the compiler:
gcc -Wall -Wextra -o myexe one.c two.c
Alternately, is there a Makefile present? If so, the author of the software
probably intends for you to use that to build the project, rather than trying to
figure out the command line on your own.
Try just running:
make
and seeing if that works. Make will show you the command lines it's running to make the build happen so that you don't have to.
The linker is part of the entire compilation system. Basically, the compiler
takes your C source files, makes sure they're syntactically correct, and turns
them into things called object files, one per source file. These object files
might refer to functions that they don't contain, like printf(), for example.
Then the linker takes all the object files and libraries and puts them together into a single binary executable that you can run. It makes sure that all the functions used are present in the files specified.
(Normally this whole process takes place behind the scenes and you don't have to
think about it. Sometimes Makefiles will generate object files that you might
see, e.g. foo.o. .o is the extension for object files on Unix, or .obj in
Windows.)
If the linker can't find a function in any of the object files or libraries, it pukes out an error. It can't call a function if it can't find it.
In this example, the code calls a function foobaz(), but the linker can't find
that in any of the object files:
Undefined symbols for architecture x86_64:
"_foobaz", referenced from:
_main in foo-133c47.o
ld: symbol(s) not found for architecture x86_64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
(Ignore the leading underscores on the function names.)
To fix, we need to figure out which file foobaz() is defined in, and make sure
to pass that filename to the compiler when we build.
If you have a .c file and you want to be able to use functions, #defines, or
globals from that file in another file, you'll need to make a header file
(.h file) to hold the function prototypes, #defines, and references to any
globals.
Example:
// square.c
long square(long x)
{
return x * x;
}If you want to use square() from a different file, you need a way for that
file to know the square() function declaration so the compiler can check to
see that you're using it correctly.
For that, we need a corresponding .h file:
// square.h
#ifndef SQUARE_H // Prevent multiple #includes
#define SQUARE_H
// Function prototypes
extern long square(long x);
#endifThe #ifndef SQUARE_H is called the guard macro, and is there to prevent the
header file from being included multiple times. (This can be a problem if you
have header files that include other header files in a cycle.) #ifndef means
"if not defined". Basically, SQUARE_H is acting as a boolean that gets set the
first time through and so prevents the content of the header file from being
included again.
All header files have wrappers like that. The name of the preprocessor variable
is conventionally FILENAME_H, but could be anything as long as it's unique in
the project.
The keyword extern indicates to the compiler that the function in question is
not defined here; it is defined in another file. In this header file, extern
is the default storage class for functions, so it's redundant. But it's really
common to see in any case.
Now that we have a header file, we can #include that from somewhere else. Use
double quotes in the #include to indicate that the compiler should look in the
current directory for the header file.
#include "square.h"
int main(void)
{
int x = square(5);When you build, you must specify all .c files on the command line:
gcc -Wall -Wextra -o main main.c square.c
IMPORTANT: Any lines shown indented in any Makefile must begin with a
single TAB character! Spaces will not work. If you use spaces to indent,
you'll likely see a Missing separator error when you try to make.
myexecutable: mysource1.c mysource2.c
gcc -Wall -Wextra -o myexecutable mysource1.c mysource2.cThe above Makefile says:
"If mysource1.c or mysource2.c are newer than myexecutable, then run the
following commands in the indented block below this line."
And by "newer", we mean they have a more up-to-date timestamp, i.e. they've been
saved more recently than myexecutable has been created.
If any of the sources are newer than the executable, the executable should be rebuilt to get it up to date. And that's what make does.
We say that myexecutable depends on mysource1.c and mysource2.c. If
either of those dependencies change, myexecutable must be rebuilt.
This also works:
myexecutable: mysource1.c mysource2.c
gcc -Wall -Wextra -o $@ $^$@ is a make macro that means "substitute whatever is left of the : right
here" (in this example, myexecutable).
$^ is a make macro that means "substitute whatever is to the right of the :
right here" (in this example, mysource1.c mysource2.c).
You can also define constants:
SRCS=mysource1.c mysource2.c
TARGET=myexecutable
$(TARGET): $(SRCS)
gcc -Wall -Wextra -o $@ $^You can have multiple recipes per Makefile:
target1: source1.c
gcc -Wall -Wextra -o $@ $^
target2: source2.c
gcc -Wall -Wextra -o $@ $^If you type make, it will build the first target in the file by default. A
target is a file that is generated by running make, i.e. a file to the left of
a :. You can also make specific targets by specifying them on the command line:
$ make target1
gcc -Wall -Wextra -o target1 source1.c
$ make target2
gcc -Wall -Wextra -o target2 source2.cIf you want all targets to get built by default, you can put a dummy first
target in that depends on the other targets. This target is called all by
convention. It typically doesn't run any commands and is only there to set up
the dependency hierarchy with the other recipes.
# Recipe `all` depends on `target1` and `target2`:
all: target1 target2
target1: source1.c
gcc -Wall -Wextra -o $@ $^
target2: source2.c
gcc -Wall -Wextra -o $@ $^
.PHONY: allThat .PHONY: all line is a GNU make extension that indicates that all is not
a real file. Normally targets refer to real files, and make will check to see if
that file exists on disk or not before trying to build it. But in this case,
all is not a file; it's just recipe we're using to get all targets to build by
default.
The way to approach it is when you think, "I need something just like
printf(), except instead of to the screen, it prints to x," then you look in
the man page and see if there's a printf() variant that suits your needs.
The first letters let you know what speciality each one has:
-
printf(): stock, no frills. -
fprintf(): "file printf"; print to a specifiedFILE*instead of tostdout. -
sprintf(): "string printf"; print to a string instead of tostdout. -
snprintf(): "string printf, with a limited count"; print to a string instead of tostdout, and also specify the maximum number of characters thatsnprintf()is allowed to store in the buffer. This is good to protect against buffer overruns, and there's a valid argument that you should never usesprintf(), preferringsnprintf()instead. -
vprintf(): "variadic printf"; anything that starts with avinprintfland has to do with variadic functions, i.e. functions with argument lists of variable lengths. These are out of scope at Lambda. - etc.
C has the feature that you have to declare a function before you can use it.
So any functions main() needs have to be declared before main(), which means
"above" it in the file.
You can also declare functions with prototypes and then put the definition of
main() before the definition of the other functions.
It's more common for C devs to put main() at the bottom of the file that
contains it, and C devs expect it that way, but it's not wrong or frowned upon
to use prototypes to put it at the top instead.
It doesn't have to. The return value from main() is the exit status of the
process. This is passed back to the program that first launched your program, so
it can do different things based on the exit status of your program.
Think of it like a way for an exiting program to pass a small piece of information (an integer) back to the program that spawned it.
0 by convention means "success". Non-zero means "failure". The idea there is
that there's typically only one way for a program to succeed, but many ways for
it to fail, and you can communicate those different ways with different exit
codes.
Note that you can also use the exit() call, passing an exit status code to it
as an argument. Using return in main() is equivalent to calling exit().
In bash, you can look at the exit status of the previous command by echoing
the $? shell variable. In the following example, we use grep incorrectly,
and it exits with status 2 to indicate that. Whereas we use ls correctly,
and it exits with successful status 0:
$ grep
usage: grep [-abcDEFGHhIiJLlmnOoqRSsUVvwxZ] [-A num] [-B num] [-C[num]]
[-e pattern] [-f file] [--binary-files=value] [--color=when]
[--context[=num]] [--directories=action] [--label] [--line-buffered]
[--null] [pattern] [file ...]
$ echo $?
2
$ ls -d .
.
$ echo $?
0At the OS level, fork() is used to create a new process, and wait() is used
to get the exit status back from that process.
Only if you want to have a program that you can run. When you first launch a
program, it looks for a function called main.
There can only be one main() in a program. (There can only be one of any
function, for that matter.)
It could be that individual files don't have a main() in them, but when the
whole project it built, main() is brought in from another source file.
Also, there's a thing called a
library which is a
collection of functionality that your program makes use of, but doesn't have a
main(), itself. Your program has the main(), and it just calls routines
that are in the library.
The C Standard Library is a
library that holds all the standard C functionality (e.g. printf(), sqrt(),
etc.) but doesn't have a main() of its own. Other programs simply use the
library.
No. The function signature for main() must be one of the following:
int main(void)
int main(int argc, char *argv[])
int main(int argc, char **argv)Note that the second two are equivalent. Use the first form if you don't need to process command line arguments.
Historically, these were also equivalent, but the second form is now obsolete:
int main(void) // OK
int main() // ObsoleteYes.
Or, more technically, at the end of every statement or expression.
C won't fill them in automatically like JavaScript will.
A pointer is a memory address. A single memory address, a single index number into your memory array.
As such, it can only point to a single byte in memory.
For single-byte and multi-byte entities, the pointer always points to the first first byte of that entity.
If you have an int made up of 4 bytes, a pointer to that int points to the
address in memory of the first byte of that int.
If you have a struct, it points to the first byte of that struct.
If you have an array of a zillion structs, it points to the first byte of the
0th struct in that array.
Pointers themselves are variables.
Variables are stored in memory.
Therefore pointers are also stored in memory.
Remember that a pointer is just an index into memory. It's just a number; in fact it's an integer number. We can store integer numbers in memory without a hassle.
The only difference between a pointer and an integer is that you can dereference the pointer to see what it's pointing to. You can't dereference an integer. In memory, they're both just stored as numbers.
1-projects/Intro-to-C-master/fizzbuzz/
Table of Contents generated with DocToc
Functions in C are not much different from functions in JavaScript. Probably the most notable difference, at least from a syntactic point of view, is that you need to specify types on all your variables and input parameters, along with needing to specify the return type of the function. Remember, C is a strongly typed language, as opposed to JavaScript which is a loosely typed language where types are entirely inferred by the interpreter. The C compiler ensures that you specify your types and that your code is consistent with the types you specify.
Here is a non-comprehensive list of C data types: https://codeforwin.org/2015/05/list-of-all-format-specifiers-in-c-programming.html
To reiterate, you might declare a function in C like this:
int foo(int param1, int param2)
{
...
return 0;
}This function signature states that it receives two integer parameters and returns an integer.
Here's another example:
void bar(int[])
{
...
}This function signature states that it receives a single integer array and doesn't return anything. You'll often see this kind of function signature when you want the function to simply mutate the input and/or print the contents of the input.
For printing output, you'll want to use the printf function, which is included in the stdlib library.
Your first task is going to be writing good ol' fizzbuzz in C! Your fizzbuzz function should receive some integer n, then loop up till n, printing out "Fizz" if the current iteration i is divisible by 3, "Buzz" if it's divisible by 5, or "FizzBuzz" if it is divisible by both 3 and 5. Additionally, for each iteration where nothing is printed, your function should increment a counter and return the result of that counter at the end of its execution.
Navigate to the fizzbuzz.c file. You'll write your code in there. When you want to test it, type make tests into your terminal (make sure you're doing this from the directory where the Makefile is located), which will run the Makefile and compile your program and, if the compilation was successful, run the tests for it as well.
1-projects/Intro-to-C-master/hangman/
Table of Contents generated with DocToc
Write a program that allows you play a game of Hangman. All of your code can be written in the hangman.c file.
The main loop of the program prints the current state of the game and then waits for input from the player. When the player types in input (either a single letter guess or a word guess), the game checks if the letter is one that is in the target word or if the word guess matches the target word. If the guess is correct, the game state updates accordingly by revealing the guess as part of the target word. If the guess is incorrect, the game state updates accordingly by showing that letter in the 'incorrect guesses' list and adding another limb to the hangman drawing.
You'll compile your program with
gcc -o hangman hangman.c
This will create an executable called hangman that you'll execute with the command ./hangman once you've successfully compiled the program.
For this implementation, your program should receive a single word parameter; that will be the word that the player is trying to guess. So running your program might look like this
./hangman antidisestablishmentarianism
This will start the game loop, which will then continue running until the player wins, the player loses, or the player exits the game.
This problem can be broken down into many subproblems. Each subproblem can be further broken down into chunks that you can think about how to implement in code. These include, but are not limited to, the following:
- Reading input from the user and recording it properly
- Figuring out how to parse command line arguments
- Properly recording game state
- Keeping track of all letters/words that have been inputted
- Recording the incorrect guesses
- Printing the proper UI given the game's current state
- Implementing the ability to accept both single letter guesses as well as entire word guesses
- Having the game UI respond appropriately when a player makes a correct / incorrect guess
- Adding the ability for the user to exit the game by typing in the proper keyword
Just in case you happen to be someone who doesn't know the rules of Hangman, we'll list them here.
The game has you guess a word. You're given 8 strikes. If you guess an incorrect letter (that you haven't already guessed before), or take a stab at guessing the entire word and don't get the correct word, that's one strike. The game keeps track of each letter that you've guessed. You win the game when you guess the correct word.
1-projects/Intro-to-C-master/malloc/
Table of Contents generated with DocToc
Remember that a few modules ago when we were talking about arrays in C being entirely static? That's a pretty big limitation since we're forced to know up front what kind of data we want to store in the array and how much data there is before we can fit it into an array. We aren't psychics here. How do we get around this?
The answer to that is the malloc function. Its signature is this:
void *malloc(size_t size);A size_t type is nothing more than a really large int for representing large sizes. The other thing to note is that the malloc function returns a void pointer. The void type simply means the type could be anything; essentially, we don't know the type up front. So malloc returns us a pointer of unspecified type that points to a chunk of memory with the specified size.
Well, if there's this void type, what's to stop us from just declaring everything as a void type? The drawback to the void type is that the compiler then can't infer much of anything about the data that a void pointer points to. It can't determine how much data a void pointer is pointing to, plus void pointers cannot be dereferenced until they are cast (their type is changed) to a known type. Basically, it won't be able to provide us nearly as many compile-time protections as it can if we have all of our types declared. The moral of the story is that the void type should only be used when you actually do not know the type of the data up front. malloc returning a void pointer is a great use-case for this.
Here are some pretty typical malloc calls:
int *100_ints = malloc(100 * sizeof(int));
char *50_chars = malloc(51);The first malloc call allocates enough space for 100 ints. The malloc call initially returns a void pointer, but it then gets cast to an int pointer on the left-hand side. You'll also note that we're using the sizeof operator in order to find the size of an individual integer, and then multiplying by the number of integers we're looking to store in order to get the total amount of memory we need. We have to do this because integers are not stored in a single byte, and integer sizes may fluctuate from platform to platform.
With the second malloc call, you'll see we don't do that. We're still performing the cast to a char pointer, but there's no call to the sizeof operator. This is because chars each fit within a single byte, so 51 bytes will hold 51 chars, which is exactly what we want. Once we have a pointer to the malloc'd memory, we can work with it exactly how we've been working with pointers.
So, we still need to know how much data we want to fit inside this chunk of malloc'd memory, which still isn't all that helpful since that's still a hefty limitation. There exist other library functions, such as realloc, which can receive a pointer to mallocd memory and then resize that chunk of memory, but for this module we're just going to stick with malloc.
We'll talk about one of the main usages of malloc in the next module.
Getting a void pointer back from a malloc call isn't the only time we'll need to deal with void pointers. Sometimes we'll need to explicitly cast a void pointer that's already referring some data, unlike the chunk of memory we're getting back from malloc call, which starts off empty and uninitialized.
A common use-case for void pointers is when we want to write a function that is generic over types, i.e., it doesn't care what the types of its inputs are. Let's assume we have the following function signature:
void foo(void *a, void *b);Here, foo takes two void pointers, which will contain some data of a certain type, but foo either doesn't know what those types are or doesn't care. If we want to do something with these two void pointers though, we'll have to explicitly cast them to some actual type we can work with. We can do that like this:
char *cast_a = (char *) a;
char *cast_b = (char *) b;Here we cast both void pointers to be char pointers. Note that this doesn't actually transform the data these two pointers point to, we aren't changing the underlying data's type. We just need to temporarily assign a concrete type to these pointers so that we can do something with them inside our foo function.
We pick char *s here because the char type is guaranteed by the C specification to be one byte each. This is desirable because it's the most granular type we can pick. If we're going to be touching some memory and not treating as the type that it actually is, then to avoid any sort of memory corruption, we want to be as granular as possible when handling that underlying data, hence the usage or chars and not some other type.
1-projects/Intro-to-C-master/pointers/
Table of Contents generated with DocToc
From the perspective of C, your entire computer is nothing more than a giant array of memory into which values can be written. Given this analogy, when we're dealing with arrays, how do we access some value stored inside of said array?
We do it with indices that point to a specific spot in the array. As it turns out, pointers in C are simply just that: indices into the giant array of memory that is your computer. More formally, a pointer is a memory address that tells the program where to go and find some variable value.
Those funky asterisks you might have seen already indicate a pointer (you might have heard them referred to as references in other languages). Let's look at the function signature we had for the reverse_string function you wrote in the strings module:
char *reverse_string(char s[])
{
...
}The char * that is in the spot where the return type of the function usually goes is saying that this function will return a pointer to an array of characters.
It turns out that pointers and arrays in C are very much interconnected, so much so that it's pretty difficult to separate the topic of pointers from arrays. Every pointer points to the first spot of a contiguous portion of memory, and as we've already established, C pretty much just treats your computer as a giant array of memory.
Indeed, there are many similarities between how you work with arrays and how you work with pointers. However, let's first talk about the differences between them.
Even though C let's you work with pointers and arrays in many of the same ways, don't think of them as synonomous. C's sizeof operator allows us to find the size of something in bytes. Let's say for example we had the following array:
int integers[] = { 9, 49, 1, 6, 10, 15 };Calling sizeof(integers) gets us the total amount of data in the array. Then let's say we had a pointer to the same chunk of data:
int *pointer_to_integers = integers;So we have an array named integers and a pointer called pointer_to_integers that points to the same spot in memory where the integers array is stored. If we were to call sizeof(pointer_to_integers), we would actually get back the size of the pointer, not the size of the data it's pointing to.
There are a few other such sorts of edge cases, but for the most part they're pretty nuanced. So while, again, you shouldn't be thinking of pointers being arrays and vice versa, you would interface with them in many of the same ways.
As showcased above, declaring a pointer is as simple as putting an asterisk after the type declaration of a variable. This signifies that we have a pointer to the declared type with the specified name.
/* Declaring two ints x and y, and an int array z */
int x = 1, y = 2, z[10];
int *ip; /* ip is a pointer to an int */
ip = &x; /* ip now points to x */
y = *ip; /* y is now 1 */
*ip = 0; /* x is now 0 */
ip = &z[0]; /* ip now points to z[0] */There's nothing new going on in the first two lines of this block. Starting at the third line with ip = &x;, we see the & operator. This means we're grabbing the address of the variable x, or in other words, we're asking for the address where the value of x (1 in this case) is being stored. We do this because ip is a pointer, which stores an address, not a value. If we did ip = x;, that would be saying "store the value of the variable x in the variable ip", which would not compile since we've declared ip to be an integer pointer, not an integer value.
In the next line, y = *ip, note that when we use the * operator not in a declaration, it signifies that we're want to grab the value of the operand. So we're saying "set the variable y to be the value of the pointer ip". Again, since ip is a pointer, it stores an address. When we prepend the * operator in front of a pointer, we're asking for the value that that pointer points to. Put another way, we're indexing into the giant array of memory that is our computer and asking for the value at the given index.
Next we have *ip = 0;. Here we're setting the value that ip points at to be 0. Before this, ip pointed to whatever x's value was, because of the line ip = &x;. So now that we changed the value at some address, any other variables or pointers that also referenced that same address also got changed! If we were to print out the value of the x variable now, it would be 0!
Lastly, we have ip = &z[0];, which declaring that ip now points to the first element of the z array. Again, we use the & operator in order to grab the address, not the value, of z[0], since ip is a pointer that stores an address.
When we index into arrays in JavaScript, we can do things like:
const someArray = [];
for (let i = 0; i < array.length; i++) {
someArray[i] = array[i + 1];
}We can index into arrays by performing arithmetic on the index. With pointers in C, we can do the exact same thing!
Let's say we have a pointer to a string like so:
char *str = "Some string";We can loop through the characters in this string by doing this:
while (*str != '\0') {
printf("%c", *str);
str++;
}This loop will print out each character in the string. Indeed, this loop is pretty much analogous to iterating through an array. More precisely though, on each iteration of this while loop, we're incrementing the spot the pointer points to by one. At the beginning of the loop, *str points to the first character in the string, S. Then, on the next iteration, it gets incremented and then prints out o. This keeps going until the pointer points to the null character, which terminates the loop.
Armed with this knowledge regarding pointers and pointer arithmetic, we can rewrite the reverse_string function from the last module to use pointers instead of allocating additional memory for the reversed string. This has the added benefit of performing the reverse in-place.
void *reverse_string(char *s)
{
char temp;
int n = string_length(s);
for (int i = 0; i < n/2; i++) {
temp = s[i];
s[i] = s[n-i-1];
s[n-i-1] = temp;
}
}Lastly, let's talk a bit about why pointers are useful. The number 1 most important reason as to why pointers exists, the motivation for their invention in the first place, is that the C compiler needs every type to have a known size at compile time. This is a pretty big restriction, and it's one that comes with the territory of working in a strongly-typed language.
But there's lots of data that we won't know the size of until runtime. What if we need to accept user input? How do we know the size of that input before the user even gives it to us? What if we need to add data to some data structure at runtime? These are all valid questions, and the workaround to them is pointers.
We can not tell the compiler the size of certain types upfront, so what we do instead is use something of a known size to refer to things of unknown size. That is exactly what pointers are. They're a type with a known size that tells us how to access something of an unknown size.
So whenever we need to hold something like a string or a data structure whose size depends on something that can only be known at runtime, you can bet such structures will be referred to by a pointer.
A slightly related use case is passing by reference vs. passing by value when we're talking about passing parameters to functions. You've probably at least heard of these terms used in other languages. Passing by value means that we're passing a copy of the value to a function as a parameter. This results in additional work and memory overhead, but means we have a fresh copy of the data to work with, which is desirable in certain scenarios.
On the flip side, passing by reference means we're passing a pointer to the data. In other words, the function doesn't have access to the data itself, but it is able to find that data in memory via the passed-in pointer. There's no need to copy the data, but then that also means the function doesn't have exclusive access to the data either.
1-projects/Intro-to-C-master/quicksort/
Table of Contents generated with DocToc
For this module, you're going to implement a quicksort function. Feel free to reference prior implementation(s) and simply transpose the code from one language to the other. Typically this is a good way to practice new languages you're trying to learn: by transposing code you've written from one language to another.
In case you haven't seen the quicksort algorithm before, here's a Python implementation that you can use as a reference:
def quicksort(alist, begin=0, end=None):
if end is None:
end = len(alist) - 1
if begin < end:
pivot = partition(alist, begin, end)
quicksort(alist, begin, pivot-1)
quicksort(alist, pivot+1, end)
def partition(alist, begin, end):
pivot = begin
for i in range(begin+1, end+1):
if alist[i] <= alist[begin]:
pivot += 1
alist[i], alist[pivot] = alist[pivot], alist[i]
alist[pivot], alist[begin] = alist[begin], alist[pivot]
return pivotKeep in mind that since Python is a higher-level language than C, it provides language features and constructs that aren't available in C. For example, the swapping syntax in Python isn't going to work in C without some additional work. The swap that you implemented earlier in the has been included in this directory in the lib.h header file though, so you can use it here to swap values within an array in-place. Another Python language feature that you can't replicate in C are the default function parameters.
Navigate to the quicksort.c file. Implement your quicksort algorithm, then type make tests to check if you have all the tests passing.
1-projects/Intro-to-C-master/strings/
Table of Contents generated with DocToc
In C, arrays are nothing more than contiguous chunks in memory that store a single type of data. Additionally, arrays are static in size, at least in their most basic form. That means that we'll typically need to know the size and/or the amount of data a particular array will be storing when we initialize it. Unlike in higher-level languages, we can't just simply declare an empty array and then start pushing elements onto it willy-nilly.
If we wanted to declare an array of integers, we might do it like so:
int int_array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };Note the syntax here. We need the square brackets after the array's name to indicate that it is an array to the compiler, and when we declare the initial values of the array, we surround them with curly braces, not square brackets.
Another way we might declare an array is the following:
int another_int_array[20];With this, we've declared a statically-sized integer array that has space for 20 integers. There's nothing in it initially, but we can now start populating it with integers (and only integers) up to it's specified capacity.
int n = 20 / sizeof(int);
for (int i = 0; i < n; i++) {
another_int_array[i] = i;
}While we allocated 20 bytes worth of space into the array, keep in mind that a single integer actually takes up more than a single byte of space in memory. To get around this, we can use the sizeof operator to find out exactly how many bytes a single int occupies on your machine, and then divide the array capacity by that to get the actual number of integers that can fit inside the array.
If we try to add more integers than the array has capacity for, we'll get a segmentation fault error, which means we've tried to access memory we don't have permission to access. That's what happens when we go outside of an array's bounds.
We'll talk later on about how to handle dynamically-sized data.
So what do arrays have to do with strings? Everything, as it turns out. Strings in C are actually nothing more than arrays of characters. In fact, when declaring a string, you might do it like this:
char[] = "Hello world!";Under the hood, this declaration becomes
char[] = { 'H', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!', '\0' };The \0 character at the end represents the null character; every C string is terminated with one of these, and in fact, if you wanted to write a function to find the number of characters in a string, you'd basically just loop through the character array and increment a counter until you found the \0 character.
IMPORTANT NOTE: So far, every language you've worked in has not differentiated between single and double quotes. In C, these actually make a difference. Single quotes delineate a single character, while double quotes delineate string literals. So for example, "a" is a string literal complete with a terminating null character at the end of it, as opposed to 'a' which is just the individual character.
The compiler will yell at you if you try to store multiple characters in single quotes.
1-projects/Intro-to-C-master/structs/
Table of Contents generated with DocToc
Another limitation that exists in C that we haven't brought up yet is the fact that arrays in C can only hold a single type of data. Being able to stick any type of data all into the same array is a feature that you probably take for granted coming from JavaScript. Well, you can't do that in C!
Enter structs. Structs are basically C's version of a poor man's object. We can store values of different types inside a struct, which is awesome, but we need to declare the types of the fields that the struct can hold up front. That being said, structs are instrumental when it comes to implementing data structures and more complex types in C.
Let's look at a simple struct definition:
struct Cat {
char *breed;
char *color;
int age;
};This declares the shape of the Cat struct. Now we'll need to create an instance of it if we want to want to actually use it. Well, what actually defines an instance of something?
In this case, an instance of a struct is some chunk of memory that has been initialized with the shape of said struct. So we'll need to allocate memory for our Cat struct. We can do that with this:
struct Cat *a_cat = malloc(sizeof(struct Cat));So we're handed a pointer to a chunk of memory that holds exactly the right amount of data for a single instance of a Cat. We take that and cast it to a pointer with the type of struct Cat since that's the type that is being held in this chunk of memory. We'll also need to go and initialize the values of our Cat instance like so:
a_cat->breed = NULL;
a_cat->color = NULL;
a_cat->age = 0;What's with these funky arrows? Coming from JavaScript, you're used to using dot notation for accessing members of an object. Structs are poor man's objects, so shouldn't dot notation work here?
The answer is that dot notation is a thing in C, but because in this case we have a pointer to a struct, we need to perform a dereference first in order to get to the actual data the struct contains. That's what the arrow syntax does. It performs a dereference first and then accesses the struct member.
Basically, you can think of it like this:
a_cat->breed == (*a_cat).breedAllocating memory for structs is one of the most important functions that malloc serves. Keep in mind though that when we declare a struct, every type in the struct needs to have a known size. Looking at the Cat struct, char *s and ints all have a known size, so the entire size of the struct can be calculated. However, we don't know the sizes of the data that the char *s may be pointing to.
Let's say we have a function called name_cat that will assign a Cat instance with a given input name. It might look like this:
void name_cat(struct Cat *cat, char *name)
{
int name_length = string_length(name);
cat->name = malloc(name_length);
string_copy(cat->name, name);
}That's right, we'll need to call malloc to allocate the appropriate amount of memory to the cat->name field, and then we can call string_copy in order to copy each character in the input name string to the memory that cat->name now points to.
Yet another abstraction that you're used to from higher-level languages is the garbage collector. A garbage collector is typically part of a languages runtime, and its job is to clean up memory that is used up by your programs.
For example, after you write some JS program that has a bunch of arrays and objects, what happens to the memory that was needed to order to hold those instances? In a high-level language, a garbage collector goes through and figures out that those arrays and objects are no longer being used. It then deallocates or frees up that memory so that it can be reused by other programs. You the programmer never needs to worry about cleaning up after yourself; it's all handled for you automatically!
C doesn't baby you around like that. It expects you to handle the clean up like the grown up you are. Learning to clean up after yourself can get difficult when you're writing more advanced programs in C. For simple programs though, it can be as simple as calling the function free after you're done with some piece of malloc'd memory.
The free function receives a pointer that points to a piece of malloc'd memory, and it deallocates it so that that memory may be re-used. As you can imagine, once some malloc'd memory has been free'd, whatever data was in that chunk of memory is gone, so make sure you're done with the data before freeing it!
Let's codify this into a simple heuristic that isn't too hard to memorize:
For every call to
mallocthere should be an accompanying call tofree.
A couple of common errors that arise when it comes to freeing memory are:
- Forgetting to call
freeon somemalloc'd piece of memory. This is a problem because that memory doesn't get cleaned up, and you end up with what's called a 'memory leak'. A single memory leak isn't the end of the world, but if you continually forget tofreeyour memory, they'll start to pile up and waste precious memory resources that could be used by other programs that actually need that memory. - Calling
freeon a pointer to memory that has already beenfree'd. This is called a 'double free', and it should be avoided because it may corrupt the state of the memory manager (which is what keeps track of all of the pieces of memory that have been handed out so far), which might cause existing blocks of memory to get corrupted or for future allocations to fail in bizarre ways (for example, the same memory getting handed out on two different successive calls of malloc).
Going back to our Cat struct, we might want to have a Cat_destroy function that will handle the cleaning up of a Cat instance for us. It'll free all the memory that was allocated during the Cat instance's lifetime.
void Cat_destroy(struct Cat *cat)
{
if (cat->name != NULL) {
free(cat->name);
}
if (cat->breed != NULL) {
free(cat->breed);
}
if (cat != NULL) {
free(cat);
}
}In all the previous example code, we've had to prepend every type we created with struct. That's because struct is part of the newly-created type's name, and as of now, we can't leave it out whenever we're using one of our own artificial types. C provides the typdef keyword which will ultimately save us some keystrokes. It will allow us to not have to prepend struct to any of our created types. Here's how we use it:
typedef struct Cat {
char *breed;
char *color;
int age;
} Cat;We'll add the typedef keyword in front of our type definition. Then, after the closing brace of our struct, we specify the aliased type we'd like for this user-created type to have. Here we'll just keep it the same as the name of the struct itself, though you could call it something else if you wanted to.
Now, whenever we want to use our Cat type, we don't need to prepend struct in front of it. The compiler now knows that when we just specify Cat that we're referring to our struct Cat type definition. It's a one-time cost that we pay when we define our types, but it'll save us a lot of keystrokes later on, especially if we're using our types a lot!
1-projects/Intro-to-C-master/
Table of Contents generated with DocToc
runtests.sh: 4: Syntax error: word unexpected (expecting "do")- Mac:
malformed objecterror when runningmake tests
Chief. Windows
If you see this error:
Running unit tests:
: not foundtests.sh: 2: ./tests/runtests.sh:
./tests/runtests.sh: 4: ./tests/runtests.sh: Syntax error: word unexpected (expecting "do")
You have two options:
-
Open the file
tests/runtests.shin VS Code in whatever subproject folder you're working in, e.g.fizzbuzz. Click on the lower right of the screen where it saysCRLF. ChooseLF. Save the file. Then the error should go away. -
You can do this from the command line with the
trcommand:
cd tests
cat runtests.sh | tr -d '\r' > runtests.tmp
mv runtests.tmp runtests.sh
The root of the problem is a setting in git that causes all newlines (LF) to
be converted to carriage-return/newline (CRLF). The script runtests.sh is a
bash script that bash runs, and bash hates \r and pukes everywhere.
To cause git to not do newline conversion for future clones, run the following:
git config --global core.autocrlf false
This is caused by an older version of the ar and ranlib packages being installed.
Sometimes these conflict with the versions installed with xcode.
If running MacPorts:
sudo port selfupdate
sudo port upgrade cctools
If running Brew:
sudo brew update
sudo brew upgrade gcc
1-projects/JavaScript-III-master/
Table of Contents generated with DocToc
This challenge focuses on using the this keyword as well as getting comfortable with prototypes by building out a fantasy themed video game.
Follow these steps to set up and work on your project:
- Create a forked copy of this project.
- Add your project manager as collaborator on Github.
- Clone your OWN version of the repository (Not Lambda's by mistake!).
- Create a new branch: git checkout -b
<firstName-lastName>. - Implement the project on your newly created
<firstName-lastName>branch, committing changes regularly. - Push commits: git push origin
<firstName-lastName>.
Follow these steps for completing your project.
- Submit a Pull-Request to merge Branch into master (student's Repo). Please don't merge your own pull request
- Add your project manager as a reviewer on the pull-request
- Your project manager will count the project as complete by merging the branch back into master.
- Complete all the exercises as described inside each assignment file.
- To test your
console.log()statements, open up the index.html file found in the assignments folder and use the developer tools to view the console.
Having a solid understanding of how this works will give you a huge advantage when you start building with more advanced frameworks. Use the this.js file to traverse through a few this problems.
The prototype challenge will focus on building prototypes for a fantasy themed game that includes mages, swordsmen, and archers. Follow the prototypes.js instructions closely to create the beginnings of what could be an awesome JavaScript game.
- Read the instructions found within the file carefully to finish the challenges.
- Remember to un-comment the objects and console logs to test your work at the bottom of the page.
1-projects/JS-Exercise-Classes/
Table of Contents generated with DocToc
This challenge focuses on using the new for ES6 class syntax.
Find the file index.js and complete the tasks until all of your tests pass.
You can use yesterday's work to help you. However, if you struggled a lot with that assignment, it is recommended that you attempt to re-write all code without "cheating" (peeking at yesterday's code or copy-pasting it).
Plan to commit & push every time you get a new test passing!. Committing often makes it SO much easier to figure out "what broke my code", and helps your TL keep track of how you're doing.
If you run into trouble while coding, fight the good fight for 20 minutes and then get on the help channel. Remember to formulate your help request in a professional manner - like you would at the job - by including error messages, screenshots, and any other pertinent information about the problem, as well as what things you have attempted already while trying to solve it.
Using VSCode and the Command Line:
- Fork repo and add TL as collaborator on Github.
- Clone your fork (not Lambda's repo by mistake!).
-
cdinto your newly cloned repository. - Create a new branch by typing
git checkout -b <firstName-lastName>. - Install dependencies by typing
npm install. - Run tests by typing
npm run test:watch. - Work on your branch, push commits and create PR as usual.

1-projects/LS-Data-Structures-I-Solution-master/
Table of Contents generated with DocToc
Topics:
- Big-O Notation (Complexity analysis)
- Stacks
- Queues
- Linked Lists
- Hash Tables
- Should have the methods:
add,remove, and a getter for the propertysize -
addshould accept a value and place it on top of the stack. -
removeshould remove and return the top value off of the stack. -
sizeshould return how many items are on the stack.
- Should have the methods:
enqueue,dequeue, and a getter for the propertysize -
enqueueshould add an item to the back of the queue. -
dequeueshould remove an item from the front of the queue. -
sizeshould return the number of items in the queue.
- Should have the methods:
addToTail,removeHead, andcontains. -
addToTailreplaces the tail with a new value that is passed in. -
removeHeadremoves and returns the head node. -
containsshould searth through the linked list and return true if a matching value is found. - The
headproperty is a reference to the first node and thetailproperty is a reference to the last node. These are the only two properties that you need to keep track of an infinite number of nodes. Build your nodes with objects.
- Should have the methods:
insert,remove, andretrieve. -
insertshould take a key value pair and add the value to the hash table. -
retrieveshould return the value associated with a key. -
removeshould removed the given key's value from the hash table. - Should properly handle collisions. If two keys map to the same index in the storage table then you should store a 2d array as the value. Make each key/value pair its own array that is nested inside of the array stored at that index on the table.
- Uncomment the final test in
hash-table.test.jsand make the hash-table rebalance. As a hash table increases in size the associated storage table will typically double in size once it reaches a certain capacity. Change the hash table so that it doubles the size of the storage table once it is 75% full. - If you used arrays as your underlying data structure for implementing stacks, queues, and hash table buckets, convert these to use linked lists instead as the underlying data structure. If you started off with linked lists, convert these to use arrays. In order to do this, you'll need to export your linked list implementation by wrapping it inside a
module.exports. Just comment out your initial implementation; don't delete perfectly good code! - Make your linked list implementation a doubly linked list.
1-projects/LS-Data-Structures-II-Solution-master/
Table of Contents generated with DocToc
Topics:
- Tree
- Graph
- Binary Search Tree
- Should have the methods:
addChild, andcontains - Each node on the tree should have a
valueproperty and achildrenarray. -
addChild(value)should accept a value and add it to that node'schildrenarray. -
contains(value)should returntrueif the tree or its children the given value. - When you add nodes to the
childrenarray usenew Tree(value)to create the node. - You can instantiate the
Treeclass inside of itself.
- Should have the methods:
insert,contains,depthFirstForEach, andbreadthFirstForEach. -
insert(value)inserts the new value at the correct location in the tree. -
contains(value)searches the tree and returnstrueif the the tree contains the specified value. -
depthFirstForEach(cb)should iterate over the tree using DFS and passes each node of the tree to the given callback function. -
breadthFirstForEach(cb)should iterate over the tree using BFS and passes each node of the tree to the given callback function (hint: you'll need to either re-implement or import a queue data structure for this).
- Should have methods named
addNode,contains,removeNode,addEdge,getEdge, andremoveEdge -
addNode(newNode, toNode)should add a new item to the graph. IftoNodeis given then the new node should share an edge with an existing nodetoNode. -
contains(value)should return true if the graph contains the given value. -
removeNode(value)should remove the specified value from the graph. -
addEdge(fromNode, toNode)should add an edge between the two specified nodes. -
getEdge(fromNode, toNode)should returntrueif an edge exists between the two specified graph nodes. -
removeEdge(fromNode, toNode)should remove the edge between the two specified nodes.
- Add a method to the
Graphclass that searches through the graph using edges. Make this search first as a depth first search and then refactor to a breadth first search. - Read up on heaps here. Then implement one!
- Read up on red-black trees here. Then implement one!
-
cdinto your project directory. -
npm installto receive your dependencies. - fire up your
mongodserver from your root dir or create adatadir in this project to store your documents from mongo there.mongod --dbpath data.
- When you open
models.jsyou'll see we've already included your Schema. You're welcome. - You'll also notice that this project comes with a
people.jsonfile, and apopulateDbScript.js. this script will grab thosepeopleand add them into your db as long as you have your mongo server up and running. - RUN:
node populateDbScript.jsget receive all your data.
- write a
GETrequest to/usersthat simply returns all the people. - write a
GETrequest to/users/:directionthat takes the given string and returns back a list of sorted data alphebetically.- hint direction can be
ascordescso in your.sort()method you'll have to conditionally check, and we are going to be sorting by userfirstName
- hint direction can be
- write a
GETrequest/user-get-friends/:idthat returns a single users's friends.
- lastly write a
PUTthat updates a usersfirstNamelastName
1-projects/nested-data-exercises-master/
Table of Contents generated with DocToc
This challenge will test your ability to work with nested Objects and Arrays.
Uses real-world 'inspired' data.
If you are experienced on this topic, expand the "💡 Challenge Yourself!" section (following the instructions.)
- Instructions
- Get Started
- Preview Test Data
- Stuck? Check Hints
Task: Complete the 10+ functions in index.js and pass all tests specified in test/index.test.js ✅
The difficulty increases as you progress.
Before you begin coding, review test data below
-
getName(character)->Luke Skywalker -
getFilmCount(character)-> 5 -
getFirstStarshipName(character)->X-wing -
getSummary(character)->Luke Skywalker, 172cm, 77kg. Featured in 5 films. -
getVehiclesCostInCreditsSumTotal(character)-> 8000 -
getStarshipPassengerAndCrewSumTotal(character)-> 27 -
getNthFilm(character, filmNumber)filmNumber=1 ->A New Hope -
getCargoCapacityTotal(character)-> 80124 -
getFastestStarshipName(character)->X-wing -
getLargestCargoStarshipModelName(character)->Lambda-class T-4a shuttle -
getSlowestVehicleOrStarshipName(character)->Imperial Speeder Bike
💡 Challenge Yourself! (expand for stretch tips)
- Research & use different patterns. (Destructuring, move common code into reusable helper methods, functional programming techniques)
- Trade completed code with a peer:
- Pair program: Take turns (30-60 min.) working through a refactor. Talk through & optimize as needed.
- Trade code for feedback! (Example format: 3&1, 3 things that you liked and 1 to improve.)
- Time yourself. See if you can beat your own time starting over. Speed run!
- See how many tests you can pass/complete before Googling or asking for help.
- When you're finished, refactor & improve readability. Write up why it is improved.
3 options are included below.
The CodeSandbox option is fast & highly recommended.
1. Fastest Option
2. Local Setup Instructions: From Command Line
- Fork & clone to your local computer
-
cdinto your newly cloned repository - Install using
npm - Run test command
git clone <insert your git clone url here>
cd <repo folder name>
npm install
npm run test:watch
#####
### Or without fs watching:
# npm testNOTE: In local development, use the file watcher command: npm run test:watch.
3. Local Setup Instructions: Run Tests in Browser
- Fork & clone to your local computer
-
cdinto your newly cloned repository - Install and Start using
npm
git clone <insert your git clone url here>
cd <repo folder name>
npm install
npm startExample data your code will be tested against.
// Complete Test Data Object (credit: https://SWAPI.co)
// Side note: Yes Star Wars 🤓 purists. It's a bit out of date. Talk to SWAPI about it.
// Focus & follow instructions above. 🤖
{
"name": "Luke Skywalker",
"height": "172",
"mass": "77",
"hair_color": "blond",
"skin_color": "fair",
"eye_color": "blue",
"birth_year": "19BBY",
"homeworld": "Tatooine",
"films": [
"A New Hope",
"The Empire Strikes Back",
"Return of the Jedi",
"Revenge of the Sith",
"The Force Awakens"
],
"species": [
"Human"
],
"vehicles": [
{
"name": "Snowspeeder",
"model": "t-47 airspeeder",
"manufacturer": "Incom corporation",
"cost_in_credits": null,
"length": "4.5",
"max_atmosphering_speed": "650",
"crew": 2,
"passengers": 0,
"cargo_capacity": "10"
},
{
"name": "Imperial Speeder Bike",
"model": "74-Z speeder bike",
"manufacturer": "Aratech Repulsor Company",
"cost_in_credits": "8000",
"length": "3",
"max_atmosphering_speed": "360",
"crew": 1,
"passengers": 1,
"cargo_capacity": "4"
}
],
"starships": [
{
"name": "X-wing",
"model": "T-65 X-wing",
"manufacturer": "Incom Corporation",
"cost_in_credits": 149999,
"length": "12.5",
"max_atmosphering_speed": "1050",
"crew": 1,
"passengers": 0,
"cargo_capacity": "110",
"consumables": "1 week",
"hyperdrive_rating": "1.0",
"MGLT": "100",
"starship_class": "Starfighter"
},
{
"name": "Imperial shuttle",
"model": "Lambda-class T-4a shuttle",
"manufacturer": "Sienar Fleet Systems",
"cost_in_credits": 240000,
"length": "20",
"max_atmosphering_speed": "850",
"crew": 6,
"passengers": 20,
"cargo_capacity": "80000",
"consumables": "2 months",
"hyperdrive_rating": "1.0",
"MGLT": "50",
"starship_class": "Armed government transport"
}
],
"created": "2014-12-09T13:50:51.644000Z",
"edited": "2014-12-20T21:17:56.891000Z",
"url": "https://swapi.co/api/people/1/"
}-
Critical: Don't make assumptions about input data types. (Convert/handle
Numbers&null)- Convert number strings into actual numbers with built-in functions
parseInt,parseFloat,Number, etc.
- Convert number strings into actual numbers with built-in functions
- Ensure your functions
return somethingUseful. - Make sure you understand the requirements. All the words used? Try list the steps in comments first.
- Don't forget the source data uses
snake_casenaming. - Pay close attention to array vs. object syntax (
vehicles[0].namevs.character.vehicles.) - Some of the functions include detailed instructions.
- You might have to infer the desired fields. Carefully read the description and function name (description included above the function.)
1-projects/Node-Express-Gmaps-Solution-Day-I-master/
Table of Contents generated with DocToc
Topics:
- APIs
- API Documentation
- Rate Limits
- Multiple requests
- Create endpoints
- Make multpile requests to third-party API
- Return result
- You will notice there is a config file that is ignored in the .gitignore, which you will be using to store your API key. You will need to import that key into your server file. DO NOT store it anywhere that will get pushed up to your repo.
- Everything else you will start from scratch.
- You will be using the Google Maps Place API to get details about any place provided by the user of your API. When the user provides you a query (example:
coffee+shops+in+Austin) you will use that query to make a request to thePlace Searchservice, and will specifically be doing aText Search Request. You will use the necessary information from the data returned from that first request, and then do a request toPlace Detailsservice, returning the detailed information to the user of your API.
- Create an endpoint
/placethat, provided a query, returns the detailed information about the first place that is in the array of places returned to you fromPlace Search. - You will be using the
node-fetchlibrary to make your requests to thePlace SearchAPI. You can use its example code in its github repo as guidance for its use.
- Create an endpoint
/placesthat, provided a query returns the detailed information about ALL places returned to you fromPlace Search.
- Places API: https://developers.google.com/places/web-service/
- Place Search: https://developers.google.com/places/web-service/search
- Place Details: https://developers.google.com/places/web-service/details
- Request Library: https://github.com/bitinn/node-fetch
1-projects/Node-Express-Gmaps-Solution-Day-II-master/
Table of Contents generated with DocToc
Topics:
- APIs
- API Documentation
- Rate Limits
- Multiple requests
- Create endpoints
- Make multpile requests to third-party API
- Return result
- You will notice there is a config file that is ignored in the .gitignore, which you will be using to store your API key. You will need to import that key into your server file. DO NOT store it anywhere that will get pushed up to your repo.
- Everything else you will start from scratch.
- You will be using the Google Maps Place API to get details about any place provided by the user of your API. When the user provides you a query (example:
coffee+shops+in+Austin) you will use that query to make a request to thePlace Searchservice, and will specifically be doing aText Search Request. You will use the necessary information from the data returned from that first request, and then do a request toPlace Detailsservice, returning the detailed information to the user of your API.
- Create an endpoint
/placethat, provided a query, returns the detailed information about the first place that is in the array of places returned to you fromPlace Search. - You will be using the
node-fetchlibrary to make your requests to thePlace SearchAPI. You can use its example code in its github repo as guidance for its use.
- Create an endpoint
/placesthat, provided a query returns the detailed information about ALL places returned to you fromPlace Search.
- Places API: https://developers.google.com/places/web-service/
- Place Search: https://developers.google.com/places/web-service/search
- Place Details: https://developers.google.com/places/web-service/details
- Request Library: https://github.com/bitinn/node-fetch
- Create an enpoint called
/travel/modethat returns the quickest method of travel given two locations, as well as the travel time. It should account for driving, walking, bicycling, and transit.
- You will need a separate key than what you've used for the Places API since it is actually a different API.
- For best results, try to pick locations that should indeed have transit available.
- Include this comparison information in the information your return from
/place.
- Distance Matrix API: https://developers.google.com/places/web-service/
- Travel Mode Section: https://developers.google.com/maps/documentation/distance-matrix/intro#travel_modes
1-projects/Python-OOP-Toy-master/
Table of Contents generated with DocToc
Note for Windows users: WSL won't work for this module!
"Object-oriented programming (OOP) is a programming paradigm based on the concept of "objects", which may contain data, in the form of fields, often known as attributes; and code, in the form of procedures, often known as methods. A feature of objects is that an object's procedures can access and often modify the data fields of the object with which they are associated (objects have a notion of "this" or "self"). In OOP, computer programs are designed by making them out of objects that interact with one another.[1][2]" --Wikipedia
In English, this means that in OOP, code is organized in logical and self contained parts that contain within them everything needed to create, store, and manipulate one very specific element of the program. When this element is needed, a copy of it is initialized according to the instructions within. This is called an object.
As with all things programming, the specific vocabulary varies from language to language, or even programmer to programmer. Some Python vocabulary:
Class: The top level organization structure in OOP. This contains all of the instructions and storage for the operations of this part of the program. A class should be self contained and all variables within the class should only be modified by methods within the class.
Method: A function that belongs to a specific class.
Constructor: A special method, defined with init() that is used to instantiate an object of this class.
Inheritance: Perhaps the most important concept in OOP, a class may inherit from another class. This gives the child class all of the variables and methods found in the parent class, or classes, automatically.
Override: If a child class needs to function slightly differently than objects of the parent class, this can be done by giving the child class a method with the same name as one found in the parent. This method will override the one defined in the parent class. Often, this is done to add child specific functionality to the method before calling the parent version of the method using super().foo(). This is commonly done with the init() method.
Self: In Python, a class refers to class-level variables and methods with the keyword self. These have scope across the entire class. Variables may also be declared normally and will have scope limited to the block of code they are declared within.
This project will demonstrate the core concepts of OOP by using a library called pygame to create a toy similar to early screensavers.
For initial setup, run:
pipenv install
pipenv shell
Then to run, use: python src/draw.py
Your instructor will demonstrate the above concepts by extending the Block class
Fill out the stubs in ball.py to extend the functionality of the ball class.
Implement simple physics to enable balls to bounce off of one another, or off of blocks. This will be HARD. If you get it 'sort of working' in any form, consider yourself to have accomplished an impressive feat!
- If
pipenv installis taking forever or erroring with TIMEOUT messages, disable your antivirus software. - If
pipenv installis puking on installing pygame:- Don't use
pipenvfor this project. Noinstall, noshell. - Download the appropriate
.whlfile from here.- Python 3.6 use the
cp36version. Python 3.7 usecp37, etc. Usepython --versionto check your version. - Try the
win32version first. If that doesn't work, the AMD version. - E.g.
pygame‑1.9.3‑cp36‑cp36m‑win32.whl
- Python 3.6 use the
- Install it with
You'll need to specify the full path, likely.
pip install pygame-[whatever].whl - Once it's installed, run the game from the
src/directory withpython draw.py
- Don't use
- If you're getting errors about
InvalidMarker:- Don't use
pipenvfor this project. Noinstall, noshell. - Run
pip3 install pygame - Once it's installed, run the game from the
src/directory withpython3 draw.py
- Don't use
1-projects/React-Todo-Solution-master/
Table of Contents generated with DocToc
-
Single Page Application
-
Compilers
-
Bundlers
-
Elements
-
Components
-
JSX
-
Package Mangers
-
CDN
-
Props and State
Table of Contents generated with DocToc
- API Documentation
- Documentation on JSX
-
Objective: At this point you have become familiar with the DOM and have built out User Interfaces HTML and CSS and some custom components. Now we're going to dive into modern front-end JavaScript development by learning about ReactJS.
-
You're going to be building a ToDo App (please hold your applause).
-
We know this may seem trivial, but the best part about this assignment is that is shows off some of the strengths of React and you can also take it as far as want so don't hold back on being creative.
-
Tool requirements
- React Dev Tools - This is a MUST you need to install this asap!
- We have everything you need for your React Developer environment in this file. We went over this in the lecture video.
- node and npm
-
npm installwill pull in all the node_modules you need once youcdinto the root directory of the project -
npm startwill start a development server on your localhost at port 3000. -
npm testwill run the tests that are included in the the project. Try to get as many of these passing as you can in the allotted time.
Your job is to write the components to complete the Todo List application and getting as many of the tests to pass as you can. The tests are expecting that you have a TodoList component that renders a Todo component for each todo item. The requirements for your Todo List app is that it should have an input field that a user can type text into and submit data in the input field in order to create a new todo item. Aside from being able to add todos, you should be able to mark any todo in the list as 'complete'. In other words, a user should be able to click on any of the todos in the list and have a strikethrough go through the individual todo. This behavior should be toggle-able, i.e. a todo item that has a strikethrough through it should still be clickable in order to allow completed items to no longer be marked as 'completed'. Once you've finished your components, you'll need to have the root App component render your TodoList component.
- All components you implement should go in the
src/componentsdirectory. - The components should be named
App.js,TodoList.jsandTodo.js(as those are the files being imported into the tests). - Think of your application as an Application Tree. App is the parent, which controlls properties/data needed for the child components. This is how modern applications are built. They're modular, separate pieces of code called components that you 'compose' together to make your app. It's awesome!
- Be sure to keep your todos in an array on state. Arrays are so awesome to work with.
- When you need to iterate over a list and return React components out as elements, you'll need to include a "key" property on the element itself.
<ElementBeingRendered key={someValue} />. Note: this is what react is doing under the hood, it needs to know how to access each element and they need to be unique so the React engine can do its thing. An example snippet that showcases this may look something like this:
this.state.todos.map((todo, i) => <AnotherComponent key={i} todo={todo} />);
Here, we're simply passing the index of each todo item as the key for the individual React component.
- Feel free to structure your "todo" data however you'd like. i.e. strings, objects etc.
- React will give you warnings in the console that urge you to squash React Anti-Patterns. But if something is completely off, you'll get stack trace errors that will force your bundle to freeze up. You can look for these in the Chrome console.
- Refactor each todo to be an object instead of a just a string. For example,
todo: {'text': 'Shop for food, 'completed': false}and when a user clicks on a todo, switch that completed flag to true. Ifcompleted === true, this should toggle the strikethrough on the 'completed' todo. The toggling functionality should work the same as when each todo was just a string. - Add the ability to delete a todo. The way this would work is each todo item should have an 'x' that should be clickable and that, when clicked, should remove the todo item from the state array, which will also remove it from the rendered list of todos.
- Take your App's styles to the next level. Start implementing as much creativity here as you'd like. You can build out your styles on a component-by-component basis eg
App.jshas a file next to it in the directory tree calledApp.scssand you define all your styles in that file. Be sure to @import these styles into theindex.scssfile. - Persist your data in
window.localStorage()hint: you may have to pass your data to a stringifier to get it to live inside thelocalStorage()of the browser. This will cause it to persist past the page refresh.
1-projects/Relational-Databases-master/
Table of Contents generated with DocToc
-
Relational Databases and PostgreSQL
- Contents
- What is a relational database?
- Relational vs NoSQL
- PostgreSQL
- SQL, Structured Query Language
-
The
WHEREClause - Column Data Types
- ACID and CRUD
- NULL and NOT NULL
- COUNT
- ORDER BY
- GROUP BY
- Keys: Primary, Foreign, and Composite
- Auto-increment Columns
- Joins
- Indexes
- Transactions
- The EXPLAIN Command
- Quick and Dirty DB Design
- Normalization and Normal Forms
- Node-Postgres
- Security
- Other Relational Databases
- Assignment: Install PostgreSQL
- Assignment: Create a Table and Use It
- Assignment: NodeJS Program to Create and Populate a Table
- Assignment: Command-line Earthquake Query Tool
- Assignment: RESTful Earthquake Data Server
- What is a relational database?
- Relational vs NoSQL
- PostgreSQL
- SQL, Structured Query Language
- Column Data Types
- ACID and CRUD
- NULL and NOT NULL
- COUNT
- ORDER BY
- GROUP BY
- Keys: Primary, Foreign, and Composite
- Auto-increment Columns
- Joins
- Indexes
- Transactions
- The EXPLAIN Command
- Quick and Dirty DB Design
- Normalization and Normal Forms
- Node-Postgres
- Security
- Other Relational Databases
- Assignment: Install PostgreSQL
- Assignment: Create a Table and Use It
- Assignment: NodeJS Program to Create and Populate a Table
- Assignment: Command-line Earthquake Query Tool
- Assignment: RESTful Earthquake Data Server
Data stored as row records in tables. Imagine a spreadsheet with column headers describing the contents of each column, and each row is a record.
A database can contain many tables. A table can contain many rows. A row can contain many columns.
Records are related to those in different tables through common columns that are present in both tables.
For example, an Employee table might have the following columns in
each record:
Employee
EmployeeID FirstName LastName DepartmentID
And a Department table might have the following columns in each
record:
Department
DepartmentID DepartmentName
Notice that both Employee and Department have a DepartmentID
column. This common column relates the two tables and can be used to
join them together with a query.
The structure described by the table definitions is known as the schema.
Compare to NoSQL databases that work with key/value pairs or are document stores.
NoSQL is a term that refers to non-relational databases, most usually document store databases. (Though it can apply to almost any kind of non-relational database.)
MongoDB is a great example of a NoSQL database.
Unfortunately, there are no definitive rules on when to choose one or the other.
Do you need ACID-compliance? Consider a relational database.
Does your schema (structure of data) change frequently? Consider NoSQL.
Does absolute consistency in your data matter, e.g. a bank, inventory management system, employee management, academic records, etc.? Consider a relational database.
Do you need easy-to-deploy high-availability? Consider NoSQL.
Do you need transactions to happen atomically? (The ability to update multiple records simultaneously?) Consider a relational database.
Do you need read-only access to piles of data? Consider NoSQL.
PostgreSQL is a venerable relational database that is freely available and world-class.
- Assignment: Install PostgreSQL
SQL ("sequel") is the language that people use for interfacing with relational databases.
A database is made up of a number of tables. Let's create a table using
SQL in the shell. Be sure to end the command with a semicolon ;.
(Note: SQL commands are often capitalized by convention, but can be lowercase.)
$ psql
psql (10.1)
Type "help" for help.
dbname=> CREATE TABLE Employee (ID INT, LastName VARCHAR(20));
Use the \dt command to show which tables exist:
dbname=> CREATE TABLE Employee (ID INT, LastName VARCHAR(20));
CREATE TABLE
dbname=> \dt
List of relations
Schema | Name | Type | Owner
--------+----------+-------+-------
public | employee | table | beej
(1 row)
Use the \d command to see what columns a table has:
dbname=> \d Employee
Table "public.employee"
Column | Type | Collation | Nullable | Default
--------------+-----------------------+-----------+----------+---------
id | integer | | |
lastname | character varying(20) | | |
dbname=> INSERT INTO Employee (ID, LastName) VALUES (10, 'Tanngnjostr');
INSERT 0 1
You can omit the column names if you're putting data in every column:
dbname=> INSERT INTO Employee VALUES (10, 'Tanngnjostr');
INSERT 0 1
Run some more inserts into the table:
INSERT INTO Employee VALUES (11, 'Alice');
INSERT INTO Employee VALUES (12, 'Bob');
INSERT INTO Employee VALUES (13, 'Charlie');
INSERT INTO Employee VALUES (14, 'Dave');
INSERT INTO Employee VALUES (15, 'Eve');You can query the table with SELECT.
Query all the rows and columnts:
dbname=> SELECT * FROM Employee;
id | lastname
----+-------------
10 | Tanngnjostr
11 | Alice
12 | Bob
13 | Charlie
14 | Dave
15 | Eve
(6 rows)
With SELECT, * means "all columns".
You can choose specific columns:
dbname=> SELECT LastName FROM Employee;
lastname
-------------
Tanngnjostr
Alice
Bob
Charlie
Dave
Eve
(6 rows)
And you can search for specific rows with the WHERE clause:
dbname=> SELECT * FROM Employee WHERE ID=12;
id | lastname
----+----------
12 | Bob
(1 row)
dbname=> SELECT * FROM Employee WHERE ID=14 OR LastName='Bob';
id | lastname
----+----------
12 | Bob
14 | Dave
(2 rows)
Finally, you can rename the output columns, if you wish:
SELECT id AS Employee ID, LastName AS Name
FROM Employee
WHERE ID=14 OR LastName='Bob';
Employee ID | Name
-------------+----------
12 | Bob
14 | DaveThe UPDATE command can update one or many rows. Restrict which rows
are updated with a WHERE clause.`
dbname=> UPDATE Employee SET LastName='Harvey' WHERE ID=10;
UPDATE 1
dbname=> SELECT * FROM Employee WHERE ID=10;
id | lastname
----+----------
10 | Harvey
(1 row)
You can update multiple columns at once:
dbname=> UPDATE Employee SET LastName='Octothorpe', ID=99 WHERE ID=14;
UPDATE 1
Delete from a table with the DELETE command. Use a WHERE clause to
restrict the delete.
CAUTION! If you don't use a WHERE clause, all rows will be deleted
from the table!
Delete some rows:
dbname=> DELETE FROM Employee WHERE ID >= 15;
DELETE 2
Delete ALL rows (Danger, Will Robinson!):
dbname=> DELETE FROM Employee;
DELETE 4
If you want to get rid of an entire table, use DROP.
WARNING! There is no going back. Table will be completely blown away. Destroyed ...by the Empire.
dbname=> DROP TABLE Employee;
DROP TABLE
- Assignment: Create a Table and Use It
You've already seen some examples of how WHERE affects SELECT,
UPDATE, and DELETE.
Normal operators like <, >, =, <=, >= are available.
For example:
SELECT * from animals
WHERE age >= 10;You can add more boolean logic with AND, OR, and affect precedence
with parentheses:
SELECT * from animals
WHERE age >= 10 AND type = 'goat';SELECT * from animals
WHERE age >= 10 AND (type = 'goat' OR type = 'antelope');The LIKE operator can be used to do pattern matching.
_ -- Match any single character
% -- Match any sequence of charactersTo select all animals that start with ab:
SELECT * from animal
WHERE name LIKE 'ab%';You probably noticed a few data types we specified with CREATE TABLE,
above. PostgreSQL has a lot of data
types.
This is an incomplete list of some of the more common types:
VARCHAR(n) -- Variable character string of max length n
BOOLEAN -- TRUE or FALSE
INTEGER -- Integer value
INT -- Same as INTEGER
DECIMAL(p,s) -- Decimal number with p digits of precision
-- and s digits right of the decimal point
REAL -- Floating point number
DATE -- Holds a date
TIME -- Holds a time
TIMESTAMP -- Holds an instant of time (date and time)
BLOB -- Binary objectThese are two common database terms.
Short for Atomicity, Consistency, Isolation, Durability. When people mention "ACID-compliance", they're generally talking about the ability of the database to accurately record transactions in the case of crash or power failure.
Atomicity: all transactions will be "all or nothing".
Consistency: all transactions will leave the database in a consistent state with all its defined rules and constraints.
Isonlation: the results of concurrent transactions is the same as if those transactions had been executed sequentially.
Durability: Once a transaction is committed, it will remain committed, despite crashes, power outages, snow, and sleet.
Short for Create, Read, Update, Delete. Describes the four basic functions of a data store.
In a relational database, these functions are handled by INSERT,
SELECT, UPDATE, and DELETE.
Columns in records can sometimes have no data, referred to by the
special keyword as NULL. Sometimes it makes sense to have NULL
columns, and sometimes it doesn't.
If you explicitly want to disallow NULL columns in your table, you can
create the columns with the NOT NULL constraint:
CREATE TABLE Employee (
ID INT NOT NULL,
LastName VARCHAR(20));
You can select a count of items in question with the COUNT operator.
For example, count the rows filtered by the WHERE clause:
SELECT COUNT(*) FROM Animals WHERE legcount >= 4;
count
-------
5Useful with GROUP BY, below.
ORDER BY which sorts SELECT results for you. Use DESC to sort in
reverse order.
SELECT * FROM Pets
ORDER BY age DESC;
name | age
-----------+-----
Rover | 9
Zaphod | 4
Mittens | 3When used with an aggregating function like COUNT, can be
used to produce groups of results.
Count all the customers in certain countries:
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country;
COUNT(CustomerID) | Country
----------------------+-----------
1123 | USA
734 | Germany
etc.Rows in a table often have one column that is called the primary key.
The value in this column applies to all the rest of the data in the
record. For example, an EmployeeID would be a great primary key,
assuming the rest of the record held employee information.
Employee
ID (Primary Key) LastName FirstName DepartmentID
To create a table and specify the primary key, use the NOT NULL and
PRIMARY KEY constraints:
CREATE TABLE Employee (
ID INT NOT NULL PRIMARY KEY,
LastName VARCHAR(20),
FirstName VARCHAR(20),
DepartmentID INT);You can always search quickly by primary key.
If a key refers to a primary key in another table, it is called a foreign key (abbreviated "FK"). You are not allowed to make changes to the database that would cause the foreign key to refer to a non-existent record.
The database uses this to maintain referential integrity.
Create a foreign key using the REFERENCES constraint. It specifies the
remote table and column the key refers to.
CREATE TABLE Department (
ID INT NOT NULL PRIMARY KEY,
Name VARCHAR(20));
CREATE TABLE Employee (
ID INT NOT NULL PRIMARY KEY,
LastName VARCHAR(20),
FirstName VARCHAR(20),
DepartmentID INT REFERENCES Department(ID));In the above example, you cannot add a row to Employee until that
DepartmentID already exists in Department's ID.
Also, you cannot delete a row from Department if that row's ID was a
DepartmentID in Employee.
Keys can also consist of more than one column. Composite keys can be created as follows:
CREATE TABLE example (
a INT,
b INT,
c INT,
PRIMARY KEY (a, c));These are columns that the database manages, usually in an ever-increasing sequence. It's perfect for generation unique, numeric IDs for primary Keys.
In some databases (e.g MySQL) this is done with an
AUTO_INCREMENTkeyword. PostgreSQL is different.
In PostgreSQL, use the SERIAL keyword to auto-generate sequential
numeric IDs for records.
CREATE TABLE Company (
ID SERIAL PRIMARY KEY,
Name VARCHAR(20));When you insert, do not specify the ID column. You must however, give a column name list that includes the remaining column names you are inserting data for. The ID column will be automatically generated by the database.
INSERT INTO Company (Name) VALUES ('My Awesome Company');This concept is extremely important to understanding how to use relational databases!
When you have two (or more) tables with data you wish to retrieve from both, you do so by using a join. These come in a number of varieties, some of which are covered here.
When you're using SELECT to make the join between two tables, you can
specify the tables specific columns are from by using the . operator.
This is especially useful when columns have the same name in the
different tables:
SELECT Animal.name, Farm.name
FROM Animal, Farm
WHERE Animal.FarmID = Farm.ID;Tables to use in these examples:
CREATE TABLE Department (
ID INT NOT NULL PRIMARY KEY,
Name VARCHAR(20));
CREATE TABLE Employee (
ID INT NOT NULL PRIMARY KEY,
Name VARCHAR(20),
DepartmentID INT);
INSERT INTO Department VALUES (10, 'Marketing');
INSERT INTO Department VALUES (11, 'Sales');
INSERT INTO Department VALUES (12, 'Entertainment');
INSERT INTO Employee VALUES (1, 'Alice', 10);
INSERT INTO Employee VALUES (2, 'Bob', 12);
INSERT INTO Employee VALUES (3, 'Charlie', 99);NOTE: Importantly, department ID 11 is not referred to from
Employee, and department ID 99 (Charlie) does not exist in
Department. This is instrumental in the following examples.
This is the most commonly-used join, by far, and is what people mean when they just say "join" with no further qualifiers.
This will return only the rows that match the requirements from both tables.
For example, we don't see "Sales" or "Charlie" in the join because neither of them match up to the other table:
dbname=> SELECT Employee.ID, Employee.Name, Department.Name
FROM Employee, Department
WHERE Employee.DepartmentID = Department.ID;
id | name | name
----+-------+---------------
1 | Alice | Marketing
2 | Bob | Entertainment
(2 rows)
Above, we used a WHERE clause to perform the inner join. This is
absolutely the most common way to do it.
There is an alternative syntax, below, that is barely ever used.
dbname=> SELECT Employee.ID, Employee.Name, Department.Name
FROM Employee INNER JOIN Department
ON Employee.DepartmentID = Department.ID;
id | name | name
----+-------+---------------
1 | Alice | Marketing
2 | Bob | Entertainment
(2 rows)
This join works like an inner join, but also returns all the rows from
the "left" table (the one after the FROM clause). It puts NULL
in for the missing values in the "right" table (the one after the
LEFT JOIN clause.)
Example:
dbname=> SELECT Employee.ID, Employee.Name, Department.Name
FROM Employee LEFT JOIN Department
ON Employee.DepartmentID = Department.ID;
id | name | name
----+---------+---------------
1 | Alice | Marketing
2 | Bob | Entertainment
3 | Charlie |
(3 rows)
Notice that even though Charlie's department isn't found in Department, his record is still listed with a NULL department name.
This join works like an inner join, but also returns all the rows from
the "right" table (the one after the RIGHT JOIN clause). It puts
NULL in for the missing values in the "right" table (the one after the
FROM clause.)
dbname=> SELECT Employee.ID, Employee.Name, Department.Name
FROM Employee RIGHT JOIN Department
ON Employee.DepartmentID = Department.ID;
id | name | name
----+-------+---------------
1 | Alice | Marketing
2 | Bob | Entertainment
| | Sales
(3 rows)
Notice that even though there are no employees in the Sales department,
the Sales name is listed with a NULL employee name.
This is a blend of a Left and Right Outer Join. All information from
both tables is selected, with NULL filling the gaps where necessary.
dbname=> SELECT Employee.ID, Employee.Name, Department.Name
FROM Employee
FULL JOIN Department
ON Employee.DepartmentID = Department.ID;
id | name | name
----+---------+---------------
1 | Alice | Marketing
2 | Bob | Entertainment
3 | Charlie |
| | Sales
(4 rows)
When searching through tables, you use a WHERE clause to narrow things
down. For speed, the columns mentioned in the WHERE clause should
either be a primary key, or a column for which an index has been
built.
Indexes help speed searches. In a large table, searching over an unindexed column will be slow.
Example of creating an index on the Employee table from the Keys section:
dbname=> CREATE INDEX ON Employee (LastName);
CREATE INDEX
dbname=> \d Employee
Table "public.employee"
Column | Type | Collation | Nullable | Default
--------------+-----------------------+-----------+----------+---------
id | integer | | not null |
lastname | character varying(20) | | |
firstname | character varying(20) | | |
departmentid | integer | | |
Indexes:
"employee_pkey" PRIMARY KEY, btree (id)
"employee_lastname_idx" btree (lastname)
Foreign-key constraints:
"employee_departmentid_fkey" FOREIGN KEY (departmentid) REFERENCES department(id)
In PostgreSQL, you can bundle a series of statements into a transaction. The transaction is executed atomically, which means either the entire transaction occurs, or none of the transaction occurs. There will never be a case where a transaction partially occurs.
Create a transaction by starting with a BEGIN statement, followed by
all the statements that are to be within the transaction.
START TRANSACTIONis generally synonymous withBEGINin SQL.
To execute the transaction ("Let's do it!"), end with a COMMIT
statement.
To abort the transaction and do nothing ("On second thought,
nevermind!") end with a ROLLBACK statement. This makes it like
nothing within the transaction ever happened.
Usually transactions happen within a program that checks for sanity and either commits or rolls back.
Pseudocode making DB calls that check if a rollback is necessary:
db("BEGIN"); // Begin transaction
db(`UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice'`);
let balance = db("SELECT balance WHERE name = 'Alice'");
// Don't let the balance go below zero:
if (balance < 0) {
db("ROLLBACK"); // Never mind!! Roll it all back.
} else {
db("COMMIT"); // Plenty of cash
}In the above example, the UPDATE and SELECT must happen at the same
time (atomically) or else another process could sneak in between and
withdraw too much money. Because it needs to be atomic, it's wrapped in
a transaction.
If you just enter a single SQL statement that is not inside a BEGIN
transaction block, it gets automatically wrapped in a BEGIN/COMMIT
block. It is a mini transaction that is COMMITted immediately.
Not all SQL databases support transactions, but most do.
The EXPLAIN command will tell you how much time the database is
spending doing a query, and what it's doing in that time.
It's a powerful command that can help tell you where you need to add indexes, change structure, or rewrite queries.
dbname=> EXPLAIN SELECT * FROM foo;
QUERY PLAN
---------------------------------------------------------
Seq Scan on foo (cost=0.00..155.00 rows=10000 width=4)
(1 row)
For more information, see the PostgreSQL EXPLAIN documentation
Designing a non-trivial database is a difficult, learned skill best left to professionals. Feel free to do small databases with minimal training, but if you get in a professional situation with a large database that needs to be designed, you should consult with people with strong domain knowledge.
That said, here are a couple pointers.
-
In general, all your tables should have a unique
PRIMARY KEYfor each row. It's common to useSERIALorAUTO_INCREMENTto make this happen. -
Keep an eye out for commonly duplicated data. If you are duplicating text data across several records, consider that maybe it should be in its own table and referred to with a foreign key.
-
Watch out for unrelated data in the same record. If it's a record in the
Employeetable but it hasDepartment_Addressas a column, that probably belongs in aDepartmenttable, referred to by a public key.
But if you really want to design database, read on to the Normalization and Normal Forms section.
[This topic is very deep and this section cannot do it full justice.]
Normalization is the process of designing or refactoring your tables for maximum consistency and minimum redundancy.
With NoSQL databases, we're used to denormalized data that is stored with speed in mind, and not so much consistency (sometimes NoSQL databases talk about eventual consistency).
Non-normalized tables are considered an anti-pattern in relational databases.
There are many normal forms. We'll talk about First, Second, and Third normal forms.
One of the reasons for normalizing tables is to avoid anomalies.
Insert anomaly: When we cannot insert a row into the table because some of the dependent information is not yet known. For example, we cannot create a new class record in the school database, because the record requires at least one student, and none have enrolled yet.
Update anomaly: When information is duplicated in the database and some rows are updated but not others. For example, say a record contains a city and a zipcode, but then the post office changes the zipcode. If some of the records are updated but not others, some cities will have the old zipcodes.
Delete anomaly: The opposite of an insert anomaly. When we delete some information and other related information must also be deleted against our will. For example, deleting the last student from a course causes the other course information to be also deleted.
By normalizing your tables, you can avoid these anomalies.
When a database is in first normal form, there is a primary key for each row, and there are no repeating sets of columns that should be in their own table.
Unnormalized (column titles on separate lines for clarity):
Farm
ID
AnimalName1 AnimalBreed1 AnimalProducesEggs1
AnimalName2 AnimalBreed2 AnimalProducesEggs2
1NF:
Farm
ID
Animal
ID FarmID[FK Farm(ID)] Name Breed ProducesEggs
Use a join to select all the animals in the farm:
SELECT Name, Farm.ID FROM Animal, Farm WHERE Farm.ID = Animal.FarmID;To be in 2NF, a table must already be in 1NF.
Additionally, all non-key data must fully relate to the key data in the table.
In the farm example, above, Animal has a Name and a key FarmID, but these two pieces of information are not related.
We can fix this by adding a table to link the other two tables together:
2NF:
Farm
ID
FarmAnimal
FarmID[FK Farm(ID)] AnimalID[FK Animal(ID)]
Animal
ID Name Breed ProducesEggs
Use a join to select all the animals in the farms:
SELECT Name, Farm.ID
FROM Animal, FarmAnimal, Farm
WHERE Farm.ID = FarmAnimal.FarmID AND
Animal.ID = FarmAnimal.AnimalID;A table in 3NF must already be in 2NF.
Additionally, columns that relate to each other AND to the key need to be moved into their own tables. This is known as removing transitive dependencies.
In the Farm example, the columns Breed and ProducesEggs are related.
If you know the breed, you automatically know if it produces eggs or
not.
3NF:
Farm
ID
FarmAnimal
FarmID[FK Farm(ID)] AnimalID[FK Animal(ID)]
BreedEggs
Breed ProducesEggs
Animal
ID Name Breed[FK BreedEggs(Breed)]
Use a join to select all the animals names that produce eggs in the farm:
SELECT Name, Farm.ID
FROM Animal, FarmAnimal, BreedEggs, Farm
WHERE Farm.ID = FarmAnimal.FarmID AND
Animal.ID = FarmAnimal.AnimalID AND
Animal.Breed = BreedEggs.Breed AND
BreedEggs.ProducesEggs = TRUE;This is a library that allows you to interface with PostgreSQL through NodeJS.
Its documentation is exceptionally good.
You might have noticed that you don't need a password to access your database that you created. This is because PostgreSQL by default uses something called peer authentication mode.
In a nutshell, it makes sure that you are logged in as yourself before you access your database. If a different user tries to access your database, they will be denied.
If you need to set up password access, see client authentication in the PostgreSQL manual
When writing code that accesses databases, there are a few rules you should follow to keep things safe.
-
Don't store database passwords or other sensitive information in your code repository. Store dummy credentials instead.
-
When building SQL queries in code, use parameterized queries. You build your query with parameter placeholders for where the query arguments will go.
This is your number-one line of defense against SQL injection attacks.
It's a seriously noob move to not use parameterized queries.
There are tons of them by Microsoft, Oracle, etc. etc.
Other popular open source databases in widespread use are:
IMPORTANT! These instructions assume you haven't already installed PostgreSQL. If you have already installed it, skip this section or Google for how to upgrade your installation.
-
Open a terminal
-
Install PostgreSQL:
brew install postgresqlIf you get install errors at this point relating to the link phase failing or missing permissions, look back in the output and see what file it failed to write.
For example, if it's failing to write something in
/usr/local/share/man-something, try setting the ownership on those directories to yourself.Example (from the command line):
$ sudo chown -R $(whoami) /usr/local/share/manThen try to install again.
-
Start the database process
-
If you want to start it every time you log in, run:
brew services start postgresql -
If you want to just start it one time right now, run:
pg_ctl -D /usr/local/var/postgres start
-
-
Create a database named the same as your username:
createdb $(whoami)- Optionally you can call it anything you want, but the shell defaults to looking for a database named the same as your user.
This database will contain tables.
Then start a shell by running psql and see if it works. You should see
this prompt:
$ psql
psql (10.1)
Type "help" for help.
dbname=>
(Use psql databasename if you created the database under something
other than your username.)
Use \l to get a list of databases.
You can enter \q to exit the shell.
Reports are that one of the easiest installs is with chocolatey. Might want to try that first.
You can also download a Windows installer from the official site.
Another option is to use the Windows Subsystem for Linux and follow the Ubuntu instructions for installing PostgreSQL.
Arch requires a bit more hands-on, but not much more. Check this out if you want to see a different Unix-y install procedure (or if you run Arch).
Launch the shell on your database, and create a table.
CREATE TABLE Employee (ID INT, FirstName VARCHAR(20), LastName VARCHAR(20));Insert some records:
INSERT INTO Employee VALUES (1, 'Alpha', 'Alphason');
INSERT INTO Employee VALUES (2, 'Bravo', 'Bravoson');
INSERT INTO Employee VALUES (3, 'Charlie', 'Charleson');
INSERT INTO Employee VALUES (4, 'Delta', 'Deltason');
INSERT INTO Employee VALUES (5, 'Echo', 'Ecoson');Select all records:
SELECT * FROM Employee;Select Employee #3's record:
SELECT * FROM Employee WHERE ID=3;Delete Employee #3's record:
DELETE FROM Employee WHERE ID=3;Use SELECT to verify the record is deleted.
Update Employee #2's name to be "Foxtrot Foxtrotson":
UPDATE Employee SET FirstName='Foxtrot', LastName='Foxtrotson' WHERE ID=2;Use SELECT to verify the update.
Using Node-Postgres, write a program that creates a table.
Run the following query from your JS code:
CREATE TABLE IF NOT EXISTS Earthquake
(Name VARCHAR(20), Magnitude REAL)Populate the table with the following data:
let data = [
["Earthquake 1", 2.2],
["Earthquake 2", 7.0],
["Earthquake 3", 1.8],
["Earthquake 4", 5.2],
["Earthquake 5", 2.9],
["Earthquake 6", 0.6],
["Earthquake 7", 6.6]
];You'll have to run an INSERT statement for each one.
Open a PostgreSQL shell (psql) and verify the table exists:
user-> \dt
List of relations
Schema | Name | Type | Owner
--------+------------+-------+-------
public | earthquake | table | user
(1 row)
Also verify it is populated:
user-> SELECT * from Earthquake;
name | magnitude
--------------+-----------
Earthquake 1 | 2.2
Earthquake 2 | 7
Earthquake 3 | 1.8
Earthquake 4 | 5.2
Earthquake 5 | 2.9
Earthquake 6 | 0.6
Earthquake 7 | 6.6
(7 rows)
Hints:
Extra Credit:
- Add an ID column to help normalize the database. Make this column
SERIALto auto-increment. - Add Date, Lat, and Lon columns to record more information about the event.
Write a tool that queries the database for earthquakes that are at least a given magnitude.
$ node earthquake 2.9
Earthquakes with magnitudes greater than or equal to 2.9:
Earthquake 2: 7
Earthquake 7: 6.6
Earthquake 4: 5.2
Earthquake 5: 2.9
Use ORDER BY Magnitude DESC to order the results in descending order
by magnitude.
Use ExpressJS and write a webserver that implements a RESTful API to access the earthquake data.
Endpoints:
/ (GET) Output usage information in HTML.
Example results:
<html>
<body>Usage: [endpoint info]</body>
</html>/minmag (GET) Output JSON list of earthquakes that are larger than the
value specified in the mag parameter. Use form encoding to pass the
data.
Example results:
{
"results": [
{
"name": "Earthquake 2",
"magnitude": 7
},
{
"name": "Earthquake 4",
"magnitude": 5.2
}
]
}Extra Credit:
/new (POST) Add a new earthquake to the database. Use form encoding to
pass name and mag. Return a JSON status message:
{ "status": "ok" }or
{ "status": "error", "message": "[error message]" }/delete (DELETE) Delete an earthquake from the database. Use form
encoding to pass name. Return status similar to /new, above.
1-projects/solutions/
Table of Contents generated with DocToc
- Run
npm installto install the prereqs. - Run
node maketableto create the DB tables. - Run
node earthquake 2.9to see all earthquakes larger than magnitude 2.9.
1-projects/webapi-ii-challenge-master/
Table of Contents generated with DocToc
- Express Routing
- Reading Request data from body and URL parameters
- Sub-routes
- API design and development.
Use Node.js and Express to build an API that performs CRUD operations on blog posts.
- Fork and Clone this repository.
- CD into the folder where you cloned the repository.
- Type
npm installto download all dependencies. - To start the server, type
npm run serverfrom the root folder (where the package.json file is). The server is configured to restart automatically as you make changes.
The data folder contains a database populated with test posts.
Database access will be done using the db.js file included inside the data folder.
The db.js publishes the following methods:
-
find(): calling find returns a promise that resolves to an array of all thepostscontained in the database. -
findById(): this method expects anidas it's only parameter and returns the post corresponding to theidprovided or an empty array if no post with thatidis found. -
insert(): calling insert passing it apostobject will add it to the database and return an object with theidof the inserted post. The object looks like this:{ id: 123 }. -
update(): accepts two arguments, the first is theidof the post to update and the second is an object with thechangesto apply. It returns the count of updated records. If the count is 1 it means the record was updated correctly. -
remove(): the remove method accepts anidas its first parameter and upon successfully deleting the post from the database it returns the number of records deleted. -
findPostComments(): the findPostComments accepts apostIdas its first parameter and returns all comments on the post associated with the post id. -
findCommentById(): accepts anidand returns the comment associated with that id. -
insertComment(): calling insertComment while passing it acommentobject will add it to the database and return an object with theidof the inserted comment. The object looks like this:{ id: 123 }. This method will throw an error if thepost_idfield in thecommentobject does not match a valid post id in the database.
Now that we have a way to add, update, remove and retrieve data from the provided database, it is time to work on the API.
A Blog Post in the database has the following structure:
{
title: "The post title", // String, required
contents: "The post contents", // String, required
created_at: Mon Aug 14 2017 12:50:16 GMT-0700 (PDT) // Date, defaults to current date
updated_at: Mon Aug 14 2017 12:50:16 GMT-0700 (PDT) // Date, defaults to current date
}A Comment in the database has the following structure:
{
text: "The text of the comment", // String, required
post_id: "The id of the associated post", // Integer, required, must match the id of a post entry in the database
created_at: Mon Aug 14 2017 12:50:16 GMT-0700 (PDT) // Date, defaults to current date
updated_at: Mon Aug 14 2017 12:50:16 GMT-0700 (PDT) // Date, defaults to current date
}- Add the code necessary to implement the endpoints listed below.
- Separate the endpoints that begin with
/api/postsinto a separateExpress Router.
Configure the API to handle to the following routes:
| Method | Endpoint | Description |
|---|---|---|
| POST | /api/posts | Creates a post using the information sent inside the request body. |
| POST | /api/posts/:id/comments | Creates a comment for the post with the specified id using information sent inside of the request body. |
| GET | /api/posts | Returns an array of all the post objects contained in the database. |
| GET | /api/posts/:id | Returns the post object with the specified id. |
| GET | /api/posts/:id/comments | Returns an array of all the comment objects associated with the post with the specified id. |
| DELETE | /api/posts/:id | Removes the post with the specified id and returns the deleted post object. You may need to make additional calls to the database in order to satisfy this requirement. |
| PUT | /api/posts/:id | Updates the post with the specified id using data from the request body. Returns the modified document, NOT the original. |
When the client makes a POST request to /api/posts:
-
If the request body is missing the
titleorcontentsproperty:- cancel the request.
- respond with HTTP status code
400(Bad Request). - return the following JSON response:
{ errorMessage: "Please provide title and contents for the post." }.
-
If the information about the post is valid:
- save the new post the the database.
- return HTTP status code
201(Created). - return the newly created post.
-
If there's an error while saving the post:
- cancel the request.
- respond with HTTP status code
500(Server Error). - return the following JSON object:
{ error: "There was an error while saving the post to the database" }.
When the client makes a POST request to /api/posts/:id/comments:
-
If the post with the specified
idis not found:- return HTTP status code
404(Not Found). - return the following JSON object:
{ message: "The post with the specified ID does not exist." }.
- return HTTP status code
-
If the request body is missing the
textproperty:- cancel the request.
- respond with HTTP status code
400(Bad Request). - return the following JSON response:
{ errorMessage: "Please provide text for the comment." }.
-
If the information about the comment is valid:
- save the new comment the the database.
- return HTTP status code
201(Created). - return the newly created comment.
-
If there's an error while saving the comment:
- cancel the request.
- respond with HTTP status code
500(Server Error). - return the following JSON object:
{ error: "There was an error while saving the comment to the database" }.
When the client makes a GET request to /api/posts:
- If there's an error in retrieving the posts from the database:
- cancel the request.
- respond with HTTP status code
500. - return the following JSON object:
{ error: "The posts information could not be retrieved." }.
When the client makes a GET request to /api/posts/:id:
-
If the post with the specified
idis not found:- return HTTP status code
404(Not Found). - return the following JSON object:
{ message: "The post with the specified ID does not exist." }.
- return HTTP status code
-
If there's an error in retrieving the post from the database:
- cancel the request.
- respond with HTTP status code
500. - return the following JSON object:
{ error: "The post information could not be retrieved." }.
When the client makes a GET request to /api/posts/:id/comments:
-
If the post with the specified
idis not found:- return HTTP status code
404(Not Found). - return the following JSON object:
{ message: "The post with the specified ID does not exist." }.
- return HTTP status code
-
If there's an error in retrieving the comments from the database:
- cancel the request.
- respond with HTTP status code
500. - return the following JSON object:
{ error: "The comments information could not be retrieved." }.
When the client makes a DELETE request to /api/posts/:id:
-
If the post with the specified
idis not found:- return HTTP status code
404(Not Found). - return the following JSON object:
{ message: "The post with the specified ID does not exist." }.
- return HTTP status code
-
If there's an error in removing the post from the database:
- cancel the request.
- respond with HTTP status code
500. - return the following JSON object:
{ error: "The post could not be removed" }.
When the client makes a PUT request to /api/posts/:id:
-
If the post with the specified
idis not found:- return HTTP status code
404(Not Found). - return the following JSON object:
{ message: "The post with the specified ID does not exist." }.
- return HTTP status code
-
If the request body is missing the
titleorcontentsproperty:- cancel the request.
- respond with HTTP status code
400(Bad Request). - return the following JSON response:
{ errorMessage: "Please provide title and contents for the post." }.
-
If there's an error when updating the post:
- cancel the request.
- respond with HTTP status code
500. - return the following JSON object:
{ error: "The post information could not be modified." }.
-
If the post is found and the new information is valid:
- update the post document in the database using the new information sent in the
request body. - return HTTP status code
200(OK). - return the newly updated post.
- update the post document in the database using the new information sent in the
To work on the stretch problems you'll need to enable the cors middleware. Follow these steps:
- add the
corsnpm module:npm i cors. - add
server.use(cors())afterserver.use(express.json()).
Create a new React application and connect it to your server:
- Use
create-react-appto create an application inside the root folder, name itclient. - From the React application connect to the
/api/postsendpoint in the API and show the list of posts. - Style the list of posts however you see fit.
2-resources/__CHEAT-SHEETS/All/
Table of Contents generated with DocToc
title: 101 category: JavaScript libraries layout: 2017/sheet updated: 2017-09-21 intro: | 101 is a JavaScript library for dealing with immutable data in a functional manner.
const isObject = require('101/isObject')
isObject({}) // → trueEvery function is exposed as a module.
See: 101
isObject({})
isString('str')
isRegExp(/regexp/)
isBoolean(true)
isEmpty({})
isfunction(x => x)
isInteger(10)
isNumber(10.1)
instanceOf(obj, 'string'){: .-three-column}
{: .-prime}
let obj = {}obj = put(obj, 'user.name', 'John')
// → { user: { name: 'John' } }pluck(name, 'user.name')
// → 'John'obj = del(obj, 'user')
// → { }pluck(state, 'user.profile.name')pick(state, ['user', 'ui'])
pick(state, /^_/)pluck returns values, pick returns subsets of objects.
put(state, 'user.profile.name', 'john')See: put
del(state, 'user.profile')
omit(state, ['user', 'data'])omit is like del, but supports multiple keys to be deleted.
hasKeypaths(state, ['user'])
hasKeypaths(state, { 'user.profile.name': 'john' })See: hasKeypaths
values(state)| and(x, y) | x && y |
| or(x, y) | x || y |
| xor(x, y) | !(!x && !y) && !(x && y) |
| equals(x, y) | x === y |
| exists(x) | !!x |
| not(x) | !x |
Useful for function composition.
compose(f, g) // x => f(g(x))
curry(f) // x => y => f(x, y)
flip(f) // f(x, y) --> f(y, x)passAll(f, g) // x => f(x) && g(x)
passAny(f, g) // x => f(x) || g(x)converge(and, [pluck('a'), pluck('b')])(x)// → and(pluck(x, 'a'), pluck(x, 'b'))See: converge
find(list, x => x.y === 2)
findIndex(list, x => ...)
includes(list, 'item')
last(list)find(list, hasProps('id'))groupBy(list, 'id')
indexBy(list, 'id')isFloat = passAll(isNumber, compose(isInteger, not))
// n => isNumber(n) && not(isInteger(n))function doStuff (object, options) { ... }
doStuffForce = curry(flip(doStuff))({ force: true })Table of Contents generated with DocToc
title: Absinthe category: Hidden layout: 2017/sheet tags: [WIP] updated: 2017-10-10 intro: | Absinthe allows you to write GraphQL servers in Elixir.
-
Schema- The root. Defines what queries you can do, and what types they return. -
Resolver- Functions that return data. -
Type- A type definition describing the shape of the data you'll return.
defmodule Blog.Web.Router do
use Phoenix.Router
forward "/", Absinthe.Plug,
schema: Blog.Schema
end{: data-line="4,5"}
Absinthe is a Plug, and you pass it one Schema.
See: Our first query
{: .-three-column}
defmodule Blog.Schema do
use Absinthe.Schema
import_types Blog.Schema.Types
query do
@desc "Get a list of blog posts"
field :posts, list_of(:post) do
resolve &Blog.PostResolver.all/2
end
end
end{: data-line="5,6,7,8,9,10"}
This schema will account for { posts { ··· } }. It returns a Type of :post, and delegates to a Resolver.
defmodule Blog.PostResolver do
def all(_args, _info) do
{:ok, Blog.Repo.all(Blog.Post)}
end
end{: data-line="3"}
This is the function that the schema delegated the posts query to.
defmodule Blog.Schema.Types do
use Absinthe.Schema.Notation
@desc "A blog post"
object :post do
field :id, :id
field :title, :string
field :body, :string
end
end{: data-line="4,5,6,7,8,9"}
This defines a type :post, which is used by the resolver.
{ user(id: "1") { ··· } }
query do
field :user, type: :user do
arg :id, non_null(:id)
resolve &Blog.UserResolver.find/2
end
end{: data-line="3"}
def find(%{id: id} = args, _info) do
···
end{: data-line="1"}
See: Query arguments
{
mutation CreatePost {
post(title: "Hello") { id }
}
}
mutation do
@desc "Create a post"
field :post, type: :post do
arg :title, non_null(:string)
resolve &Blog.PostResolver.create/2
end
end{: data-line="1"}
See: Mutations
- Absinthe website (absinthe-graphql.org)
- GraphQL cheatsheet (devhints.io)
Table of Contents generated with DocToc
Allows you to filter listings by a certain scope. {: .-setup}
scope :draft
scope :for_approvalscope :public, if: ->{ current_admin_user.can?(...) }
scope "Unapproved", :pending
scope("Published") { |books| books.where(:published: true) }filter :email
filter :usernameYou can define custom actions for models. {: .-setup}
before_filter only: [:show, :edit, :publish] do
@post = Post.find(params[:id])
endmember_action :publish, method: :put do
@post.publish!
redirect_to admin_posts_path, notice: "The post '#{@post}' has been published!"
endindex do
column do |post|
link_to 'Publish', publish_admin_post_path(post), method: :put
end
endaction_item only: [:edit, :show] do
@post = Post.find(params[:id])
link_to 'Publish', publish_admin_post_path(post), method: :put
endcolumn :foocolumn :title, sortable: :name do |post|
strong post.title
endstatus_tag "Done" # Gray
status_tag "Finished", :ok # Green
status_tag "You", :warn # Orange
status_tag "Failed", :error # RedActiveAdmin.register Post do
actions :index, :edit
# or: config.clear_action_items!
endTable of Contents generated with DocToc
title: adb (Android Debug Bridge) category: CLI layout: 2017/sheet weight: -1 authors:
- github: ZackNeyland updated: 2018-03-06
| Command | Description |
|---|---|
adb devices |
Lists connected devices |
adb devices -l |
Lists connected devices and kind |
| --- | --- |
adb root |
Restarts adbd with root permissions |
adb start-server |
Starts the adb server |
adb kill-server |
Kills the adb server |
adb remount |
Remounts file system with read/write access |
adb reboot |
Reboots the device |
adb reboot bootloader |
Reboots the device into fastboot |
adb disable-verity |
Reboots the device into fastboot |
wait-for-device can be specified after adb to ensure that the command will run once the device is connected.
-s can be used to send the commands to a specific device when multiple are connected.
$ adb wait-for-device devices
List of devices attached
somedevice-1234 device
someotherdevice-1234 device
$ adb -s somedevice-1234 root
| Command | Description |
|---|---|
adb logcat |
Starts printing log messages to stdout |
adb logcat -g |
Displays current log buffer sizes |
adb logcat -G <size> |
Sets the buffer size (K or M) |
adb logcat -c |
Clears the log buffers |
adb logcat *:V |
Enables ALL log messages (verbose) |
adb logcat -f <filename> |
Dumps to specified file |
$ adb logcat -G 16M
$ adb logcat *:V > output.log
| Command | Description |
|---|---|
adb push <local> <remote> |
Copies the local to the device at remote |
adb pull <remote> <local> |
Copies the remote from the device to local |
$ echo "This is a test" > test.txt
$ adb push test.txt /sdcard/test.txt
$ adb pull /sdcard/test.txt pulledTest.txt
| Command | Description |
|---|---|
adb shell <command> |
Runs the specified command on device (most unix commands work here) |
adb shell wm size |
Displays the current screen resolution |
adb shell wm size WxH |
Sets the resolution to WxH |
adb shell pm list packages |
Lists all installed packages |
adb shell pm list packages -3 |
Lists all installed 3rd-party packages |
adb shell monkey -p app.package.name |
Starts the specified package |
Table of Contents generated with DocToc
title: Google Analytics's analytics.js category: Analytics layout: 2017/sheet updated: 2017-10-29 intro: | Google Analytics's analytics.js is deprecated.
ga('create', 'UA-XXXX-Y', 'auto')
ga('create', 'UA-XXXX-Y', { userId: 'USER_ID' })ga('send', 'pageview')
ga('send', 'pageview', { 'dimension15': 'My custom dimension' })ga('send', 'event', 'button', 'click', {color: 'red'});ga('send', 'event', 'button', 'click', 'nav buttons', 4);
/* ^category ^action ^label ^value */ga('send', 'exception', {
exDescription: 'DatabaseError',
exFatal: false,
appName: 'myapp',
appVersion: '0.1.2'
})Table of Contents generated with DocToc
mixpanel.identify('284');
mixpanel.people.set({ $email: 'hi@gmail.com' });
mixpanel.register({ age: 28, gender: 'male' }); /* set common properties */mixpanel {: .-crosslink}
ga('create', 'UA-XXXX-Y', 'auto');
ga('create', 'UA-XXXX-Y', { userId: 'USER_ID' });ga('send', 'pageview');
ga('send', 'pageview', { 'dimension15': 'My custom dimension' });analytics.js {: .-crosslink}
Table of Contents generated with DocToc
- Lists (ng-repeat)
- Model (ng-model)
- Defining a module
- Controller with protection from minification
- Service
- Directive
- HTTP
<html ng-app="nameApp"> <ul ng-controller="MyListCtrl">
<li ng-repeat="phone in phones">
{{phone.name}}
</li>
</ul> <select ng-model="orderProp">
<option value="name">Alphabetical</option>
<option value="age">Newest</option>
</select> App = angular.module('myApp', []);
App.controller('MyListCtrl', function ($scope) {
$scope.phones = [ ... ];
}); App.controller('Name', [
'$scope',
'$http',
function ($scope, $http) {
}
]);
a.c 'name', [
'$scope'
'$http'
($scope, $http) ->
] App.service('NameService', function($http){
return {
get: function(){
return $http.get(url);
}
}
});In controller you call with parameter and will use promises to return data from server.
App.controller('controllerName',
function(NameService){
NameService.get()
.then(function(){})
}) App.directive('name', function(){
return {
template: '<h1>Hello</h1>'
}
});In HTML will use <name></name> to render your template <h1>Hello</h1>
App.controller('PhoneListCtrl', function ($scope, $http) {
$http.get('/data.json').success(function (data) {
$scope.phones = data;
})
});References:
Table of Contents generated with DocToc
{: .-one-column}
mkdir -p gif
mplayer -ao null -vo gif89a:outdir=gif $INPUT
mogrify -format gif *.png
gifsicle --colors=256 --delay=4 --loopcount=0 --dither -O3 gif/*.gif > ${INPUT%.*}.gif
rm -rf gifYou'll need mplayer, imagemagick and gifsicle. This converts frames to .png, then turns them into an animated gif.
mplayer -ao null -ss 0:02:06 -endpos 0:05:00 -vo gif89a:outdir=gif videofile.mp4See -ss and -endpos.
Table of Contents generated with DocToc
\033[#m
0 clear
1 bold
4 underline
5 blink
30-37 fg color
40-47 bg color
1K clear line (to beginning of line)
2K clear line (entire line)
2J clear screen
0;0H move cursor to 0;0
1A move up 1 line
0 black
1 red
2 green
3 yellow
4 blue
5 magenta
6 cyan
7 white
hide_cursor() { printf "\e[?25l"; }
show_cursor() { printf "\e[?25h"; }Table of Contents generated with DocToc
- Ruby installation (github.com)
- Postgres installation (github.com)
- GitLab installation (github.com)
Table of Contents generated with DocToc
title: "Ansible quickstart" category: Ansible layout: 2017/sheet description: | A quick guide to getting started with your first Ansible playbook.
$ brew install ansible # OSX
$ [sudo] apt install ansible # elsewhereAnsible is available as a package in most OS's.
See: Installation
~$ mkdir setup
~$ cd setupMake a folder for your Ansible files.
See: Getting started
[sites]
127.0.0.1
192.168.0.1
192.168.0.2
192.168.0.3This is a list of hosts you want to manage, grouped into groups. (Hint: try
using localhost ansible_connection=local to deploy to your local machine.)
See: Intro to Inventory
- hosts: 127.0.0.1
user: root
tasks:
- name: install nginx
apt: pkg=nginx state=present
- name: start nginx every bootup
service: name=nginx state=started enabled=yes
- name: do something in the shell
shell: echo hello > /tmp/abc.txt
- name: install bundler
gem: name=bundler state=latestSee: Intro to Playbooks
~/setup$ ls
hosts
playbook.yml
~/setup$ ansible-playbook -i hosts playbook.yml
PLAY [all] ********************************************************************
GATHERING FACTS ***************************************************************
ok: [127.0.0.1]
TASK: [install nginx] *********************************************************
ok: [127.0.0.1]
TASK: start nginx every bootup] ***********************************************
ok: [127.0.0.1]
...
- Getting started with Ansible (lowendbox.com)
- Getting started (docs.ansible.com)
- Intro to Inventory (docs.ansible.com)
- Intro to Playbooks (docs.ansible.com)
Table of Contents generated with DocToc
title: Ansible modules category: Ansible layout: 2017/sheet prism_languages: [yaml] updated: 2017-10-03
{% raw %}
---
- hosts: production
remote_user: root
tasks:
- ···Place your modules inside tasks.
- apt: pkg=vim state=present- apt:
pkg: vim
state: present- apt: >
pkg=vim
state=presentDefine your tasks in any of these formats. One-line format is preferred for short declarations, while maps are preferred for longer.
- apt:
pkg: nodejs
state: present # absent | latest
update_cache: yes
force: no- apt:
deb: "https://packages.erlang-solutions.com/erlang-solutions_1.0_all.deb"- apt_repository:
repo: "deb https://··· raring main"
state: present- apt_key:
id: AC40B2F7
url: "http://···"
state: present- git:
repo: git://github.com/
dest: /srv/checkout
version: master
depth: 10
bare: yesSee: git module
- git_config:
name: user.email
scope: global # local | system
value: hi@example.comSee: git_config module
- user:
state: present
name: git
system: yes
shell: /bin/sh
groups: admin
comment: "Git Version Control"See: user module
- service:
name: nginx
state: started
enabled: yes # optionalSee: service module
- shell: apt-get install nginx -y- shell: echo hello
args:
creates: /path/file # skip if this exists
removes: /path/file # skip if this is missing
chdir: /path # cd here before running- shell: |
echo "hello there"
echo "multiple lines"See: shell module
- script: /x/y/script.sh
args:
creates: /path/file # skip if this exists
removes: /path/file # skip if this is missing
chdir: /path # cd here before runningSee: script module
- file:
path: /etc/dir
state: directory # file | link | hard | touch | absent
# Optional:
owner: bin
group: wheel
mode: 0644
recurse: yes # mkdir -p
force: yes # ln -nfsSee: file module
- copy:
src: /app/config/nginx.conf
dest: /etc/nginx/nginx.conf
# Optional:
owner: user
group: user
mode: 0644
backup: yesSee: copy module
- template:
src: config/redis.j2
dest: /etc/redis.conf
# Optional:
owner: user
group: user
mode: 0644
backup: yesSee: template module
- name: do something locally
local_action: shell echo hello- debug:
msg: "Hello {{ var }}"See: debug module {% endraw %}
Table of Contents generated with DocToc
roles/
common/
tasks/
handlers/
files/ # 'copy' will refer to this
templates/ # 'template' will refer to this
meta/ # Role dependencies here
vars/
defaults/
main.yml
Table of Contents generated with DocToc
{% raw %}
$ sudo mkdir /etc/ansible
$ sudo vim /etc/ansible/hosts
[example]
192.0.2.101
192.0.2.102
$ ansible-playbook playbook.yml
- hosts: all
user: root
sudo: no
vars:
aaa: bbb
tasks:
- ...
handlers:
- ...
tasks:
- include: db.yml
handlers:
- include: db.yml user=timmy
handlers:
- name: start apache2
action: service name=apache2 state=started
tasks:
- name: install apache
action: apt pkg=apache2 state=latest
notify:
- start apache2
- host: lol
vars_files:
- vars.yml
vars:
project_root: /etc/xyz
tasks:
- name: Create the SSH directory.
file: state=directory path=${project_root}/home/.ssh/
only_if: "$vm == 0"
- host: xxx
roles:
- db
- { role:ruby, sudo_user:$user }
- web
# Uses:
# roles/db/tasks/*.yml
# roles/db/handlers/*.yml
- name: my task
command: ...
register: result
failed_when: "'FAILED' in result.stderr"
ignore_errors: yes
changed_when: "result.rc != 2"
vars:
local_home: "{{ lookup('env','HOME') }}"
{% endraw %}
Table of Contents generated with DocToc
CACHE MANIFEST
# version
CACHE:
http://www.google.com/jsapi
/assets/app.js
/assets/bg.png
NETWORK:
*
Note that Appcache is deprecated!
See: Using the application cache (developer.mozilla.org)
Table of Contents generated with DocToc
title: AppleScript updated: 2018-12-06 layout: 2017/sheet category: macOS prism_languages: [applescript]
osascript -e "..."display notification "X" with title "Y"-- This is a single line comment# This is another single line comment(*
This is
a multi
line comment
*)-- default voice
say "Hi I am a Mac"-- specified voice
say "Hi I am a Mac" using "Zarvox"-- beep once
beep-- beep 10 times
beep 10-- delay for 5 seconds
delay 5Table of Contents generated with DocToc
<meta property="al:ios:url" content="applinks://docs" />
<meta property="al:ios:app_store_id" content="12345" />
<meta property="al:ios:app_name" content="App Links" />
<meta property="al:android:url" content="applinks://docs" />
<meta property="al:android:app_name" content="App Links" />
<meta property="al:android:package" content="org.applinks" />
<meta property="al:web:url" content="http://applinks.org/documentation" />
iosipadiphoneandroidwindows_phoneweb
Table of Contents generated with DocToc
- Tables
- Fields
where(restriction)select(projection)-
join limit/offset- Aggregates
order- With ActiveRecord
- Clean code with arel
- Reference
users = Arel::Table.new(:users)
users = User.arel_table # ActiveRecord modelusers[:name]
users[:id]users.where(users[:name].eq('amy'))
# SELECT * FROM users WHERE users.name = 'amy'users.project(users[:id])
# SELECT users.id FROM usersIn ActiveRecord (without Arel), if :photos is the name of the association, use joins
users.joins(:photos)In Arel, if photos is defined as the Arel table,
photos = Photo.arel_table
users.join(photos)
users.join(photos, Arel::Nodes::OuterJoin).on(users[:id].eq(photos[:user_id]))users.joins(:photos).merge(Photo.where(published: true))If the simpler version doesn't help and you want to add more SQL statements to it:
users.join(
users.join(photos, Arel::Nodes::OuterJoin)
.on(photos[:user_id].eq(users[:id]).and(photos[:published].eq(true)))
)multiple joins with the same table but different meanings and/or conditions
creators = User.arel_table.alias('creators')
updaters = User.arel_table.alias('updaters')
photos = Photo.arel_table
photos_with_credits = photos
.join(photos.join(creators, Arel::Nodes::OuterJoin).on(photos[:created_by_id].eq(creators[:id])))
.join(photos.join(updaters, Arel::Nodes::OuterJoin).on(photos[:assigned_id].eq(updaters[:id])))
.project(photos[:name], photos[:created_at], creators[:name].as('creator'), updaters[:name].as('editor'))
photos_with_credits.to_sql
# => "SELECT `photos`.`name`, `photos`.`created_at`, `creators`.`name` AS creator, `updaters`.`name` AS editor FROM `photos` INNER JOIN (SELECT FROM `photos` LEFT OUTER JOIN `users` `creators` ON `photos`.`created_by_id` = `creators`.`id`) INNER JOIN (SELECT FROM `photos` LEFT OUTER JOIN `users` `updaters` ON `photos`.`updated_by_id` = `updaters`.`id`)"
# after the request is done, you can use the attributes you named
# it's as if every Photo record you got has "creator" and "editor" fields, containing creator name and editor name
photos_with_credits.map{|x|
"#{photo.name} - copyright #{photo.created_at.year} #{photo.creator}, edited by #{photo.editor}"
}.join('; ')users.take(5) # => SELECT * FROM users LIMIT 5
users.skip(4) # => SELECT * FROM users OFFSET 4users.project(users[:age].sum) # .average .minimum .maximum
users.project(users[:id].count)
users.project(users[:id].count.as('user_count'))users.order(users[:name])
users.order(users[:name], users[:age].desc)
users.reorder(users[:age])User.arel_table
User.where(id: 1).arelMost of the clever stuff should be in scopes, e.g. the code above could become:
photos_with_credits = Photo.with_creator.with_editorYou can store requests in variables then add SQL segments:
all_time = photos_with_credits.count
this_month = photos_with_credits.where(photos[:created_at].gteq(Date.today.beginning_of_month))
recent_photos = photos_with_credits.where(photos[:created_at].gteq(Date.today.beginning_of_month)).limit(5)Table of Contents generated with DocToc
{: .-three-column}
| Shortcut | Description |
|---|---|
⌘\ |
Toggle tree |
⌘⇧\ |
Reveal current file |
| {: .-shortcuts} |
| Shortcut | Description |
|---|---|
⌘/ |
Toggle comments |
| {: .-shortcuts} |
| Shortcut | Description |
|---|---|
⌘k ←
|
Split pane to the left |
| --- | --- |
⌘⌥= |
Grow pane |
⌘⌥- |
Shrink pane |
| --- | --- |
^⇧← |
Move tab to left |
| {: .-shortcuts} |
| Shortcut | Description |
|---|---|
^m |
Go to matching bracket |
^] |
Remove brackets from selection |
^⌘m |
Select inside brackets |
⌥⌘. |
Close tag |
| {: .-shortcuts} |
| Shortcut | Description |
|---|---|
^⌥↓ |
Jump to declaration under cursor |
^⇧r |
Show tags |
| {: .-shortcuts} |
Symbols view enables Ctags support for Atom.
See: Symbols view
| ^⇧9 | Show Git pane |
| ^⇧8 | Show GitHub pane |
{: .-shortcuts}
| Shortcut | Description |
|---|---|
⌘d |
Select word |
⌘l |
Select line |
| --- | --- |
⌘↓ |
Move line down |
⌘↑ |
Move line up |
| --- | --- |
⌘⏎ |
New line below |
⌘⇧⏎ |
New line above |
| --- | --- |
⌘⇧k |
Delete line |
⌘⇧d |
Duplicate line |
| {: .-shortcuts} |
| Shortcut | Description |
|---|---|
⌘⇧p |
Command palette |
⌘⇧a |
Add project folder |
| --- | --- |
⌘n |
New file |
⌘⇧n |
New window |
| --- | --- |
⌘f |
Find in file |
⌘⇧f |
Find in project |
⌘t |
Search files in project |
| {: .-shortcuts} |
- For Windows and Linux,
⌘is theControlkey. - For macOS, it's the
Commandkey.
- For Windows and Linux,
⌥is theAltkey. - For macOS, it's the
Optionkey.
Table of Contents generated with DocToc
Create action creators in flux standard action format. {: .-setup}
increment = createAction('INCREMENT', amount => amount)
increment = createAction('INCREMENT') // sameincrement(42) === { type: 'INCREMENT', payload: 42 }// Errors are handled for you:
err = new Error()
increment(err) === { type: 'INCREMENT', payload: err, error: true }redux-actions {: .-crosslink}
A standard for flux action objects. An action may have an error, payload and meta and nothing else.
{: .-setup}
{ type: 'ADD_TODO', payload: { text: 'Work it' } }
{ type: 'ADD_TODO', payload: new Error(), error: true }flux-standard-action {: .-crosslink}
Dispatch multiple actions in one action creator. {: .-setup}
store.dispatch([
{ type: 'INCREMENT', payload: 2 },
{ type: 'INCREMENT', payload: 3 }
])redux-multi {: .-crosslink}
Combines reducers (like combineReducers()), but without namespacing magic. {: .-setup}
re = reduceReducers(
(state, action) => state + action.number,
(state, action) => state + action.number
)
re(10, { number: 2 }) //=> 14reduce-reducers {: .-crosslink}
Logs actions to your console. {: .-setup}
// Nothing to see hereredux-logger {: .-crosslink}
Pass promises to actions. Dispatches a flux-standard-action. {: .-setup}
increment = createAction('INCREMENT') // redux-actions
increment(Promise.resolve(42))redux-promise {: .-crosslink}
Sorta like that, too. Works by letting you pass thunks (functions) to dispatch(). Also has 'idle checking'.
{: .-setup}
fetchData = (url) => (dispatch) => {
dispatch({ type: 'FETCH_REQUEST' })
fetch(url)
.then((data) => dispatch({ type: 'FETCH_DONE', data })
.catch((error) => dispatch({ type: 'FETCH_ERROR', error })
})
store.dispatch(fetchData('/posts'))// That's actually shorthand for:
fetchData('/posts')(store.dispatch)redux-promises {: .-crosslink}
Pass side effects declaratively to keep your actions pure. {: .-setup}
{
type: 'EFFECT_COMPOSE',
payload: {
type: 'FETCH'
payload: {url: '/some/thing', method: 'GET'}
},
meta: {
steps: [ [success, failure] ]
}
}redux-effects {: .-crosslink}
Pass "thunks" to as actions. Extremely similar to redux-promises, but has support for getState. {: .-setup}
fetchData = (url) => (dispatch, getState) => {
dispatch({ type: 'FETCH_REQUEST' })
fetch(url)
.then((data) => dispatch({ type: 'FETCH_DONE', data })
.catch((error) => dispatch({ type: 'FETCH_ERROR', error })
})
store.dispatch(fetchData('/posts'))// That's actually shorthand for:
fetchData('/posts')(store.dispatch, store.getState)// Optional: since fetchData returns a promise, it can be chained
// for server-side rendering
store.dispatch(fetchPosts()).then(() => {
ReactDOMServer.renderToString(<MyApp store={store} />)
})redux-thunk {: .-crosslink}
Table of Contents generated with DocToc
aws ec2 describe-instances
aws ec2 start-instances --instance-ids i-12345678c
aws ec2 terminate-instances --instance-ids i-12345678c
aws s3 ls s3://mybucket
aws s3 rm s3://mybucket/folder --recursive
aws s3 cp myfolder s3://mybucket/folder --recursive
aws s3 sync myfolder s3://mybucket/folder --exclude *.tmp
aws ecs create-cluster
--cluster-name=NAME
--generate-cli-skeleton
aws ecs create-service
brew install awscli
aws configure
aws configure --profile project1
aws configure --profile project2
- .elasticbeanstalk/config.yml - application config
- .elasticbeanstalk/dev-env.env.yml - environment config
eb config
See: http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/command-options.html
- http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/customize-containers.html
- http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/customize-containers-ec2.html
Table of Contents generated with DocToc
.on('event', callback)
.on('event', callback, context).on({
'event1': callback,
'event2': callback
}).on('all', callback).once('event', callback) // Only happens onceobject.off('change', onChange) // just the `onChange` callback
object.off('change') // all 'change' callbacks
object.off(null, onChange) // `onChange` callback for all events
object.off(null, null, context) // all callbacks for `context` all events
object.off() // allobject.trigger('event')view.listenTo(object, event, callback)
view.stopListening()-
Collection:
-
add(model, collection, options) -
remove(model, collection, options) -
reset(collection, options) -
sort(collection, options)
-
-
Model:
-
change(model, options) -
change:[attr](model, value, options) -
destroy(model, collection, options) -
error(model, xhr, options)
-
-
Model and collection:
-
request(model, xhr, options) -
sync(model, resp, options)
-
-
Router:
-
route:[name](params) -
route(router, route, params)
-
// All attributes are optional
var View = Backbone.View.extend({
model: doc, tagName: 'div',
className: 'document-item',
id: "document-" + doc.id,
attributes: { href: '#' }, el: 'body', events: {
'click button.save': 'save',
'click .cancel': function() { ··· },
'click': 'onclick'
}, constructor: function() { ··· },
render: function() { ··· }
})view = new View()
view = new View({ el: ··· })view.$el.show()
view.$('input')view.remove()view.delegateEvents()
view.undelegateEvents()// All attributes are optional
var Model = Backbone.Model.extend({
defaults: {
'author': 'unknown'
},
idAttribute: '_id',
parse: function() { ··· }
})var obj = new Model({ title: 'Lolita', author: 'Nabokov' })var obj = new Model({ collection: ··· })obj.id
obj.cid // → 'c38' (client-side ID)obj.clone()obj.hasChanged('title')
obj.changedAttributes() // false, or hash
obj.previousAttributes() // false, or hash
obj.previous('title')obj.isNew()obj.set({ title: 'A Study in Pink' })
obj.set({ title: 'A Study in Pink' }, { validate: true, silent: true })
obj.unset('title')obj.get('title')
obj.has('title')
obj.escape('title') /* Like .get() but HTML-escaped */obj.clear()
obj.clear({ silent: true })obj.save()
obj.save({ attributes })
obj.save(null, {
silent: true, patch: true, wait: true,
success: callback, error: callback
})obj.destroy()
obj.destroy({
wait: true,
success: callback, error: callback
})obj.toJSON()obj.fetch()
obj.fetch({ success: callback, error: callback })var Model = Backbone.Model.extend({
validate: function(attrs, options) {
if (attrs.end < attrs.start) {
return "Can't end before it starts"
}
}
}){: data-line="2"}
obj.validationError //=> "Can't end before it starts"
obj.isValid()
obj.on('invalid', function (model, error) { ··· })// Triggered on:
obj.save()
obj.set({ ··· }, { validate: true })var Model = Backbone.Model.extend({
// Single URL (string or function)
url: '/account',
url: function() { return '/account' }, // Both of these two work the same way
url: function() { return '/books/' + this.id }),
urlRoot: '/books'
})var obj = new Model({ url: ··· })
var obj = new Model({ urlRoot: ··· }){: .-one-column}
- Backbone website (backbonejs.org)
- Backbone patterns (ricostacruz.com)
Table of Contents generated with DocToc
Here are some badges for open source projects.
Travis
[](https://travis-ci.org/rstacruz/REPO)
CodeClimate (shields.io)
[](https://codeclimate.com/github/rstacruz/REPO
"CodeClimate")
Coveralls (shields.io)
[](https://coveralls.io/r/rstacruz/REPO)
Travis (shields.io)
[](https://travis-ci.org/rstacruz/REPO "See test builds")
NPM (shields.io)
[](https://npmjs.org/package/REPO "View this project on npm")
Ruby gem (shields.io)
[](http://rubygems.org/gems/GEMNAME "View this project in Rubygems")
Gitter chat
[](https://gitter.im/REPO/GITTERROOM "Gitter chat")
Gitter chat (shields.io)
[]( https://gitter.im/USER/REPO )
david-dm
[](https://david-dm.org/rstacruz/REPO)
[](http://opensource.org/licenses/MIT)
[](http://opensource.org/licenses/MIT)
Support
-------
__Bugs and requests__: submit them through the project's issues tracker.<br>
[]( https://github.com/USER/REPO/issues )
__Questions__: ask them at StackOverflow with the tag *REPO*.<br>
[]( http://stackoverflow.com/questions/tagged/REPO )
__Chat__: join us at gitter.im.<br>
[]( https://gitter.im/USER/REPO )
Installation
------------
Add [nprogress.js] and [nprogress.css] to your project.
```html
<script src='nprogress.js'></script>
<link rel='stylesheet' href='nprogress.css'/>
```
NProgress is available via [bower] and [npm].
$ bower install --save nprogress
$ npm install --save nprogress
[bower]: http://bower.io/search/?q=nprogress
[npm]: https://www.npmjs.org/package/nprogress
**PROJECTNAME** © 2014+, Rico Sta. Cruz. Released under the [MIT] License.<br>
Authored and maintained by Rico Sta. Cruz with help from contributors ([list][contributors]).
> [ricostacruz.com](http://ricostacruz.com) ·
> GitHub [@rstacruz](https://github.com/rstacruz) ·
> Twitter [@rstacruz](https://twitter.com/rstacruz)
[MIT]: http://mit-license.org/
[contributors]: http://github.com/rstacruz/nprogress/contributors
-
Everything: http://shields.io/
-
Version badge (gems, npm): http://badge.fury.io/
-
Dependencies (ruby): http://gemnasium.com/
-
Code quality (ruby): http://codeclimate.com/
-
Test coverage: https://coveralls.io/
Table of Contents generated with DocToc
- Getting started
- Parameter expansions
- Loops
- Functions
- Conditionals
- Arrays
- Dictionaries
- Options
- History
- Miscellaneous
- Also see
title: Bash scripting category: CLI layout: 2017/sheet tags: [Featured] updated: 2020-07-05 keywords:
- Variables
- Functions
- Interpolation
- Brace expansions
- Loops
- Conditional execution
- Command substitution
{: .-three-column}
{: .-intro}
This is a quick reference to getting started with Bash scripting.
- Learn bash in y minutes (learnxinyminutes.com)
- Bash Guide (mywiki.wooledge.org)
#!/usr/bin/env bash
NAME="John"
echo "Hello $NAME!"NAME="John"
echo $NAME
echo "$NAME"
echo "${NAME}!"NAME="John"
echo "Hi $NAME" #=> Hi John
echo 'Hi $NAME' #=> Hi $NAMEecho "I'm in $(pwd)"
echo "I'm in `pwd`"
# Samegit commit && git push
git commit || echo "Commit failed"{: id='functions-example'}
get_name() {
echo "John"
}
echo "You are $(get_name)"See: Functions
{: id='conditionals-example'}
if [[ -z "$string" ]]; then
echo "String is empty"
elif [[ -n "$string" ]]; then
echo "String is not empty"
fiSee: Conditionals
set -euo pipefail
IFS=$'\n\t'See: Unofficial bash strict mode
echo {A,B}.js| Expression | Description |
|---|---|
{A,B} |
Same as A B
|
{A,B}.js |
Same as A.js B.js
|
{1..5} |
Same as 1 2 3 4 5
|
See: Brace expansion
{: .-three-column}
name="John"
echo ${name}
echo ${name/J/j} #=> "john" (substitution)
echo ${name:0:2} #=> "Jo" (slicing)
echo ${name::2} #=> "Jo" (slicing)
echo ${name::-1} #=> "Joh" (slicing)
echo ${name:(-1)} #=> "n" (slicing from right)
echo ${name:(-2):1} #=> "h" (slicing from right)
echo ${food:-Cake} #=> $food or "Cake"length=2
echo ${name:0:length} #=> "Jo"See: Parameter expansion
STR="/path/to/foo.cpp"
echo ${STR%.cpp} # /path/to/foo
echo ${STR%.cpp}.o # /path/to/foo.o
echo ${STR%/*} # /path/to
echo ${STR##*.} # cpp (extension)
echo ${STR##*/} # foo.cpp (basepath)
echo ${STR#*/} # path/to/foo.cpp
echo ${STR##*/} # foo.cpp
echo ${STR/foo/bar} # /path/to/bar.cppSTR="Hello world"
echo ${STR:6:5} # "world"
echo ${STR: -5:5} # "world"SRC="/path/to/foo.cpp"
BASE=${SRC##*/} #=> "foo.cpp" (basepath)
DIR=${SRC%$BASE} #=> "/path/to/" (dirpath)| Code | Description |
|---|---|
${FOO%suffix} |
Remove suffix |
${FOO#prefix} |
Remove prefix |
| --- | --- |
${FOO%%suffix} |
Remove long suffix |
${FOO##prefix} |
Remove long prefix |
| --- | --- |
${FOO/from/to} |
Replace first match |
${FOO//from/to} |
Replace all |
| --- | --- |
${FOO/%from/to} |
Replace suffix |
${FOO/#from/to} |
Replace prefix |
# Single line comment: '
This is a
multi line
comment
'| Expression | Description |
|---|---|
${FOO:0:3} |
Substring (position, length) |
${FOO:(-3):3} |
Substring from the right |
| Expression | Description |
|---|---|
${#FOO} |
Length of $FOO
|
STR="HELLO WORLD!"
echo ${STR,} #=> "hELLO WORLD!" (lowercase 1st letter)
echo ${STR,,} #=> "hello world!" (all lowercase)
STR="hello world!"
echo ${STR^} #=> "Hello world!" (uppercase 1st letter)
echo ${STR^^} #=> "HELLO WORLD!" (all uppercase)| Expression | Description |
|---|---|
${FOO:-val} |
$FOO, or val if unset (or null) |
${FOO:=val} |
Set $FOO to val if unset (or null) |
${FOO:+val} |
val if $FOO is set (and not null) |
${FOO:?message} |
Show error message and exit if $FOO is unset (or null) |
Omitting the : removes the (non)nullity checks, e.g. ${FOO-val} expands to val if unset otherwise $FOO.
{: .-three-column}
for i in /etc/rc.*; do
echo $i
donefor ((i = 0 ; i < 100 ; i++)); do
echo $i
donefor i in {1..5}; do
echo "Welcome $i"
donefor i in {5..50..5}; do
echo "Welcome $i"
donecat file.txt | while read line; do
echo $line
donewhile true; do
···
done{: .-three-column}
myfunc() {
echo "hello $1"
}# Same as above (alternate syntax)
function myfunc() {
echo "hello $1"
}myfunc "John"myfunc() {
local myresult='some value'
echo $myresult
}result="$(myfunc)"myfunc() {
return 1
}if myfunc; then
echo "success"
else
echo "failure"
fi| Expression | Description |
|---|---|
$# |
Number of arguments |
$* |
All postional arguments (as a single word) |
$@ |
All postitional arguments (as separate strings) |
$1 |
First argument |
$_ |
Last argument of the previous command |
Note: $@ and $* must be quoted in order to perform as described.
Otherwise, they do exactly the same thing (arguments as separate strings).
See Special parameters.
{: .-three-column}
Note that [[ is actually a command/program that returns either 0 (true) or 1 (false). Any program that obeys the same logic (like all base utils, such as grep(1) or ping(1)) can be used as condition, see examples.
| Condition | Description |
|---|---|
[[ -z STRING ]] |
Empty string |
[[ -n STRING ]] |
Not empty string |
[[ STRING == STRING ]] |
Equal |
[[ STRING != STRING ]] |
Not Equal |
| --- | --- |
[[ NUM -eq NUM ]] |
Equal |
[[ NUM -ne NUM ]] |
Not equal |
[[ NUM -lt NUM ]] |
Less than |
[[ NUM -le NUM ]] |
Less than or equal |
[[ NUM -gt NUM ]] |
Greater than |
[[ NUM -ge NUM ]] |
Greater than or equal |
| --- | --- |
[[ STRING =~ STRING ]] |
Regexp |
| --- | --- |
(( NUM < NUM )) |
Numeric conditions |
| Condition | Description |
|---|---|
[[ -o noclobber ]] |
If OPTIONNAME is enabled |
| --- | --- |
[[ ! EXPR ]] |
Not |
[[ X && Y ]] |
And |
| `[[ X |
| Condition | Description |
|---|---|
[[ -e FILE ]] |
Exists |
[[ -r FILE ]] |
Readable |
[[ -h FILE ]] |
Symlink |
[[ -d FILE ]] |
Directory |
[[ -w FILE ]] |
Writable |
[[ -s FILE ]] |
Size is > 0 bytes |
[[ -f FILE ]] |
File |
[[ -x FILE ]] |
Executable |
| --- | --- |
[[ FILE1 -nt FILE2 ]] |
1 is more recent than 2 |
[[ FILE1 -ot FILE2 ]] |
2 is more recent than 1 |
[[ FILE1 -ef FILE2 ]] |
Same files |
# String
if [[ -z "$string" ]]; then
echo "String is empty"
elif [[ -n "$string" ]]; then
echo "String is not empty"
else
echo "This never happens"
fi# Combinations
if [[ X && Y ]]; then
...
fi1 function createCounter() {
2 let counter = 0;
3
4 return function() {
5 counter += 1;
6 return counter;
7 }
8 }
9
10 var counter = createCounter();
11
12 console.log("counter1: " + counter());
13 console.log("counter1: " + counter());
14
15 const counter2 = createCounter();
16 console.log("counter2: " + counter2());t0: before line 1
{
counter: undefined
}t1: after line 1
{
counter: undefined,
createCounter: [Function#1#createCounter]
}t2: line 10
{
counter: [Function#2#anon],
createCounter: [Function#1#createCounter],
CCFS: { // createCounterFunctionScope
counter: 0,
anon: [Function#2#anon]
}
}t3: after line 12
{
counter: [Function#2#anon],
createCounter: [Function#1#createCounter],
CCFS: { // createCounterFunctionScope
counter: 1,
anon: [Function#2#anon]
AFS: { // anonymousFunctionScope
}
}
}t4: after line 13
{
counter: [Function#2#anon],
createCounter: [Function#1#createCounter],
CCFS: { // createCounterFunctionScope
counter: 2,
anon: [Function#2#anon],
AFS: { // returned
},
AFS2: { // anonymousFunctionScope
}
}
}t5: after line 15
{
counter: [Function#2#anon],
createCounter: [Function#1#createCounter],
CCFS: { // createCounterFunctionScope
counter: 2,
anon: [Function#2#anon],
AFS: { // returned
},
AFS2: { // returned
}
},
CCFS2: { // createCounterFunctionScope #2!
counter: 0,
anon: [Function#3#anon]
},
counter2: [Function#3#anon]
}t6: after line 16
{
counter: [Function#2#anon],
createCounter: [Function#1#createCounter],
CCFS: { // createCounterFunctionScope
counter: 2,
anon: [Function#2#anon],
AFS: { // returned
},
AFS2: { // returned
}
},
CCFS2: { // createCounterFunctionScope #2!
counter: 1,
anon: [Function#3#anon],
AFS: { // anonymousFunctionScope
},
},
counter2: [Function#3#anon]
}// Scope
// scope answers the question of where are my functions and variables available to me
const cohort = 'Web43';
console.log( cohort )
// const and let are not attached to the window object but var is
// global variables are defined outside of functions or blocks of code and would be available to me anywhere in my program
// functions are scoped similar to the way variable are scoped
let study = 'HTML and CSS';
function printThree() {
let study = 'JavaScript';
return `We are studying ${study}`;
}
console.log( printThree() );
console.log(study)
/*
| 12: 18: 41 | bryan @LAPTOP - 9 LGJ3JGS: [ d1 ] d1_exitstatus: 1 __________________________________________________________o >
node w3d1.js
Web43
We are studying JavaScript
HTML and CSS
*/
// const dog = 'Ada'
// function callDog () {
// console.log( dog );
// callDog();
// }
// puppy();
//var can be redeclared and updated
/*
var
- can be redecleared
- can be updated
- is function scoped
let
- cannot be redecleared
- can be updated
- is block scoped
const
- cannot be redecleared
- cannot be updated
- is block scoped
*/
if ( 1 === 1 ) {
var answer = true;
} // these {} are a block of code and let and const cannot escape them
// console.log(answer);
for ( let i = 0; i < 5; i++ ) {
console.log( i );
}
if(1 === 1){
var answer = true;
} // these {} are a block of code and let and const cannot escape them
// console.log(answer);
// for(let i = 0; i < 5; i++){
// console.log(i);
// }
// console.log(i);
/*using const until we can't and then let but avoid var*/
function sayHi(name){
var hello = 'hi';
function yell(){
console.log(name.toUpperCase());
}
yell();
}
sayHi('Natalie');
// yell();
console.log(hello);Variables are used to store information to be referenced and manipulated in a computer program. A variable's sole purpose is to label and store data in computer memory. Up to this point we've been using the let keyword as our only way of declaring a JavaScript variable. It's now time to expand your tool set to learn about the different kinds of JavaScript variables you can use!
When you finish this reading, you should be able to:
-
Identify the three keywords used to declare a variable in JavaScript
-
Explain the differences between
const,letandvar -
Identify the difference between function and block-scoped variables
-
Paraphrase the concept of hoisting in regards to function and block-scoped
variables
All the code you write in JavaScript is evaluated. A variable always evaluates to the value it contains no matter how you declare it.
In the beginning there was var. The var keyword used to be the only way to declare a JavaScript variable. However, in ECMAScript 2015 JavaScript introduced two new ways of declaring JavaScript variables: let and const. Meaning, in JavaScript there are three different ways to declare a variable. Each of these keywords has advantages and disadvantages and we will now talk about each keyword at length.
-
let: any variables declared with the keywordletallows you to reassignthat variable. Variable declared using
letis scoped within a block. -
const: any variables declared with the keywordconst_will not allow youto reassign_ that variable. Variable declared using
constis scoped withina block.
-
var: Avardeclared variable may or may not be reassigned, and thevariable is scoped to a function.
For this course and for your programming career moving forward we recommend you always use let & const. These two words allow us to be the most clear with our intentions for the variable we are creating.
A wonderful definition of hoisting by Mabishi Wakio, "Hoisting is a JavaScript mechanism where variables and function declarations are moved to the top of their scope before code execution."
What this means is that when you run JavaScript code the variables and function declarations will be hoisted to the top of their particular scope. This is important because const and let are block-scoped while var is function-scoped.
Let's start by talking more about all const, let, and var before we dive into why the difference of scopes and hoisting is important.
When JavaScript was young the only available variable was var. The var keyword creates function-scoped variables. That means when you use the var keyword to declare a variable that variable will be confined to the scope of the current function.
Here is a simple example of declaring a var variable within a function:
function test() {
var a = 10;
console.log(a); // => 10
}One of the drawbacks of using var is that it is a less indicative way of defining a variable.
Hoisting with function-scoped variables
Let's take a look at what hoisting does to a function-scoped variable:
function test() {
console.log(hoistedVar); // => undefined
var hoistedVar = 10;
}
test();Huh - that's weird. You'd expect an error from referring to a variable like hoistedVar before it's defined, something like: ReferenceError: hoistedVar is not defined. However this is not the case because of hoisting in JavaScript!
So essentially hoisting will isolate and, in the computer's memory, will declare a variable as the top of it's scope. With a function-scoped variable, var, the name of the variable will be hoisted to the top of the function. In the above snippet, since hoistedVar is declared using the var keyword the hoistedVar's scope is the test function. To be clear what is being hoisted is the declaration, not the assignment itself.
In JavaScript, all variables defined with the var keyword have an initial value of undefined. Here is a translation of how JavaScript would deal with hoisting in the above test function:
function test() {
// JavaScript will declare the variable *in computer memory* at the top of it's scope
var hoistedVar;
// since hoisting declared the variable above we now get
// the value of 'undefined'
console.log(hoistedVar); // => undefined
var hoistedVar = 10;
}When you are declaring a variable with the keyword let or const you are declaring a variable that exists within block scope. Blocks in JavaScript are denoted by curly braces({}). The following examples create a block scope: if statements, while loops, switch statements, and for loops.
Using the keyword let
We can use let to declare re-assignable block-scoped variables. You are, of course, very familiar with let so let's take a look at how let works within a block scope:
function blockScope() {
let test = "upper scope";
if (true) {
let test = "lower scope";
console.log(test); // "lower scope"
}
console.log(test); // "upper scope"
}In the example above we can see that the test variable was declared twice using the keyword let but since they were declared within different scopes they have different values.
JavaScript will raise a SyntaxError if you try to declare the same let variable twice in one block.
if (true) {
let test = "this works!";
let test = "nope!"; // Identifier 'test' has already been declared
}Whereas if you try the same example with var:
var test = "this works!";
var test = "nope!";
console.log(test); // prints "nope!"We can see above that var will allow you to redeclare a variable twice which can lead to some very confusing and frustrating debugging.
Feel free to peruse the documentation for the keyword let for more examples.
Using the keyword const
We use const to declare block-scoped variables that can not be reassigned. In JavaScript variables that cannot be reassigned are called constants. Constants should be used for values that will not be re-declared or re-assigned.
Properties of constants:
-
They are block-scoped like
let. -
JavaScript enforces constants by raising an error if you try to reassign them.
-
Trying to redeclare a constant with a
varorletby the same name willalso raise an error.
Let's look at a quick example of what happens when trying to reassign a constant:
> const favFood = "cheeseboard pizza"; // Initializes a constant
undefined
> const favFood = "inferior food"; // Re-initialization raises an error
TypeError: Identifier 'favFood' has already been declared
> let favFood = "other inferior food"; // Re-initialization raises an error
TypeError: Identifier 'favFood' has already been declared
> favFood = "deep-dish pizza"; // Re-assignment raises an error
TypeError: Assignment to constant variable.We cannot reassign a constant, but constants that are assigned to Reference types are mutable. The name binding of a constant is immutable. For example, if we set a constant equal to an Reference type like an object, we can still modify that object:
const animals = {};
animals.big = "beluga whale"; // This works!
animals.small = "capybara"; // This works!
animals = { big: "beluga whale" }; // Will error because of the reassignmentConstants cannot be reassigned but, just like with let, new constants of the same names can be declared within nested scopes.
Take a look at the following for an example:
const favFood = "cheeseboard pizza";
console.log(favFood);
if (true) {
// This works! Declaration is scoped to the `if` block
const favFood = "noodles";
console.log(favFood); // Prints "noodles"
}
console.log(favFood); // Prints 'cheeseboard pizza'Just like with let when you use const twice in the same block JavaScript will raise a SyntaxError.
if (true) {
const test = "this works!";
const test = "nope!"; // SyntaxError: Identifier 'test' has already been declared
}Hoisting with block-scoped variables
When JavaScript ES6 introduced new ways of declaring a variable using let and const the idea of block-level hoisting was also introduced. Block scope hoisting allows developers to avoid previous debugging debacles that naturally happened from using var.
Let's take a look at what hoisting does to a block-scoped variable:
if (true) {
console.log(str); // => Uncaught ReferenceError: Cannot access 'str' before initialization
const str = "apple";
}Looking at the above we can see that an explicit error is thrown if you attempt to use a block-scoped variable before it was declared. This is the typical behavior in a lot of programming languages - that a variable cannot be referred to until initialized to a value.
However, JavaScript is still performing hoisting with block-scoped declared variables. The difference lies is how it initializes them. Meaning that let and const variables are not initialized to the value of undefined.
The time before a let or const variable is declared, but not used is called the Temporal Dead Zone. A very cool name for a simple idea. Variables declared using let and const are not initialized until their definitions are evaluated. Meaning, you will get an error if you try to reference a let or const declared variable before it is evaluated.
Let's look at one more example that should illuminate the presence of the Temporal Dead Zone:
var str = "not apple";
if (true) {
console.log(str); //Uncaught ReferenceError: Cannot access 'str' before initialization
let str = "apple";
}In the above example we can see that inside the if block the let declared variable, str, throws an error. Showing that the error thrown by a let variable in the temporal dead zone takes precedence over any scope chaining that would attempt to go to the outer scope to find a value for the str variable.
Let's now take a deeper look at the comparison of using function vs. block scoped variables.
Let's start with a simple example:
function partyMachine() {
var string = "party";
console.log("this is a " + string);
}Looks good so far but let's take that example a step farther and see some of the less fun parts of the var keyword in terms of scope:
function partyMachine() {
var string = "party";
if (true) {
// since var is not block-scoped and not constant
// this assignment sticks!
var string = "bummer";
}
console.log("this is a " + string);
}
partyMachine(); // => "this is a bummer"We can see in the above example how the flexibility of var can ultimately be a bad thing. Since var is function-scoped and can be reassigned and re-declared without error it is very easy to overwrite variable values by accident.
This is the problem that ES6 introduced let and const to solve. Since let and const are block-scoped it's a lot easier to avoid accidentally overwriting variable values.
Let's take a look at the example function above rewritten using let and const:
function partyMachine() {
const string = "party";
if (true) {
// this variable is restricted to the scope of this block
const string = "bummer";
}
console.log("this is a " + string);
}
partyMachine(); // => "this is a party"If you leave off a declaration when initializing a variable, it will become a global. Do not do this. We declare variables using the keywords var, let, and const to ensure that our variables are declared within a proper scope. Any variables declared without these keywords will be declared on the global scope.
JavaScript has a single global scope, which means all of the files from your projects and any libraries you use will all be sharing the same scope. Every time a variable is declared on the global scope, the chance of a name collision increases. If we are unaware of the global variables in our code, we may accidentally overwrite variables.
Let's look at a quick example showing why this is a bad idea:
function good() {
let x = 5;
let y = "yay";
}
function bad() {
y = "Expect the unexpected (eg. globals)";
}
function why() {
console.log(y); // "Expect the unexpected (eg. globals)""
console.log(x); // Raises an error
}
why();Limiting global variables will help you create code that is much more easily maintainable. Strive to write your functions so that they are self-contained and not reliant on outside variables. This will also be a huge help in allowing us test each function by itself.
One of our jobs as programmers is to write code that can be integrated easily within a team. In order to do that, we need to limit the number of globally declared variables in our code as much as possible, to avoid accidental name collisions.
Sloppy programmers use global variables, and you are not working so hard in order to be a sloppy programmer!
The scope of a program in JavaScript is the set of variables that are available for use within the program. If a variable or other expression is not in the current scope, then it is unavailable for use. If we declare a variable, this variable will only be valid in the scope where we declared it. We can have nested scopes, but we'll see that in a little bit.
When we declare a variable in a certain scope, it will evaluate to a specific value in that scope. We have been using the concept of scope in our code all along! Now we are just giving this concept a name.
By the end of this reading you should be able to predict the evaluation of code that utilizes local scope, block scope, lexical scope, and scope chaining
Before we start talking about different types of scope we'll be talking about the two main advantages that scope gives us:
-
Security - Scope adds security to our code by ensuring that variables can
only be accessed by pre-defined parts of our programs.
-
Reduced Variable Name Collisions - Scope reduces variable name
collisions, also known as namespace collisions, by ensuring you can use the
same variable name multiple times in different scopes without accidentally
overwriting those variable's values.
There are three types of scope in JavaScript: global scope, local scope, and block scope.
Let's start by talking about the widest scope there is: global scope. The global scope is represented by the window object in the browser and the global object in Node.js. Adding attributes to these objects makes them available throughout the entire program. We can show this with a quick example:
let myName = "Apples";
console.log(myName);
// this myName references the myName variable from this scope,
// so myName will evaluate to "Apples"The variable myName above is not inside a function, it is just lying out in the open in our code. The myName variable is part of global scope. The Global scope is the largest scope that exists, it is the outermost scope that exists.
While useful on occasion, global variables are best avoided. Every time a variable is declared on the global scope, the chance of a name collision increases. If we are unaware of the global variables in our code, we may accidentally overwrite variables.
The scope of a function is the set of variables that are available for use within that function. We call the scope within a function: local scope. The local scope of a function includes:
- the function's arguments
- any local variables declared inside the function
- any variables that were already declared when the function was defined
In JavaScript when we enter a new function we enter a new scope:
// global scope
let myName = "global";
function function1() {
// function1's scope
let myName = "func1";
console.log("function1 myName: " + myName);
}
function function2() {
// function2's scope
let myName = "func2";
console.log("function2 myName: " + myName);
}
function1(); // function1 myName: func1
function2(); // function2 myName: func2
console.log("global myName: " + myName); // global myName: globalIn the code above we are dealing with three different scopes: the global scope, function1, and function2. Since each of the myName variables were declared in separate scopes, we are allowed to reuse variable names without any issues. This is because each of the myName variables is bound to their respective functions.
A block in JavaScript is denoted by a pair of curly braces ({}). Examples of block statements in JavaScript are if conditionals or for and while loops.
When using the keywords let or const the variables defined within the curly braces will be block scoped. Let's look at an example:
// global scope
let dog = "woof";
// block scope
if (true) {
let dog = "bowwow";
console.log(dog); // will print "bowwow"
}
console.log(dog); // will print "woof"A key scoping rule in JavaScript is the fact that an inner scope does have access to variables in the outer scope.
Let's look at a simple example:
let name = "Fiona";
// we aren't passing in or defining and variables
function hungryHippo() {
console.log(name + " is hungry!");
}
hungryHippo(); // => "Fiona is hungry"So when the hungryHippo function is declared a new local scope will be created for that function. Continuing on that line of thought what happens when we refer to name inside of hungryHippo? If the name variable is not found in the immediate scope, JavaScript will search all of the accessible outer scopes until it finds a variable name that matches the one we are referencing. Once it finds the first matching variable, it will stop searching. In JavaScript this is called scope chaining.
Now let's look at an example of scope chaining with nested scope. Just like functions in JavaScript, a scope can be nested within another scope. Take a look at the example below:
// global scope
let person = "Rae";
// sayHello function's local scope
function sayHello() {
let person = "Jeff";
// greet function's local scope
function greet() {
console.log("Hi, " + person + "!");
}
greet();
}
sayHello(); // logs 'Hi, Jeff!'In the example above, the variable person is referenced by greet, even though it was never declared within greet! When this code is executed JavaScript will attempt to run the greet function - notice there is no person variable within the scope of the greet function and move on to seeing if that variable is defined in an outer scope.
Notice that the greet function prints out Hi, Jeff! instead of Hi, Rae!. This is because JavaScript will start at the inner most scope looking for a variable named person. Then JavaScript will work it's way outward looking for a variable with a matching name of person. Since the person variable within sayHello is in the next level of scope above greet JavaScript then stops it's scope chaining search and assigns the value of the person variable.
Functions such as greet that use (ie. capture) variables like the person variable are called closures. We'll be talking a lot more about closures very soon!
Important An inner scope can reference outer variables, but an outer scope cannot reference inner variables:
function potatoMaker() {
let name = "potato";
console.log(name);
}
potatoMaker(); // => "potato"
console.log(name); // => ReferenceError: name is not definedThere is one last important concept to talk about when we refer to scope - and that is lexical scope. Whenever you run a piece of JavaScript that code is first parsed before it is actually run. This is known as the lexing time. In the lexing time your parser resolves variable names to their values when functions are nested.
The main take away is that lexical scope is determined at lexing time so we can determine the values of variables without having to run any code. JavaScript is a language without dynamic scoping. This means that by looking at a piece of code we can determine the values of variables just by looking at the different scopes involved.
Let's look at a quick example:
function outer() {
let x = 5;
function inner() {
// here we know the value of x because scope chaining will
// go into the scope above this one looking for variable named x.
// We do not need to run this code in order to determine the value of x!
console.log(x);
}
inner();
}In the inner function above we don't need to run the outer function to know what the value of x will be because of lexical scoping.
The scope of a program in JavaScript is the set of variables that are available for use within the program. Due to lexical scoping we can determine the value of a variable by looking at various scopes without having to run our code. Scope Chaining allows code within an inner scope to access variables declared in an outer scope.
There are three different scopes:
- global scope - the global space is JavaScript
- local scope - created when a function is defined
- block scope - created by entering a pair of curly braces



| Languages |
|
| Libraries |
|
| Frameworks |
|
| Databases |
|
| Testing |
|
| Other |
|








- GitHub
- Gitlab
- Bitbucket
- code pen
- Glitch
- Replit
- Redit
- runkit
- stack-exchange
- Netlify
- Medium
- webcomponents.dev
- npm
- Upwork
- AngelList
- Quora
- dev.to
- Observable Notebooks
- Notation
- StackShare
- Plunk
- Dribble
➤ Blog:
I write articles for:
-
CodeX
-
Analytics Vidhya
-
Star Gazers
-
JavaScript in Plain English
-
Geek Culture
-
Level Up Coding
-

About Me









![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
-
🔭 Contract Web Development Relational Concepts
-
🌱 I'm currently learning React/Redux, Python, Java, Express, jQuery
-
👯 I'm looking to collaborate on Any web audio or open source educational tools.
-
🤝 I'm looking for help with Learning React
-
👨💻 All of my projects are available at https://bgoonz.github.io/
-
📝 I regularly write articles on medium && Web-Dev-Resource-Hub
-
💬 Ask me about Anything:
-
📫 How to reach me bryan.guner@gmail.com
-
⚡ Fun fact I played Bamboozle Music Festival at the Meadowlands Stadium Complex when I was 14.
A Random Walk Down Wall Street
Hitchhiker's Guide To The Galaxy
Designing recording software/hardware and using it
Try harder and listen to your parents more (the latter bit of advice would be almost certain to fall on deaf ears lol)
I built a platform that listens to a guitarist's performance and automatically triggers guitar effects at the appropriate time in the song.
Is it to basic to say Tesla... I know they're prevalent now but I've been an avid fan since as early as 2012.
Having really good ideas and forgetting them moments later.
A text
Creating things that change my every day life.
Modern Physics... almost changed my major after that class... but at the end of the day engineering was a much more fiscally secure avenue.
Learned to code ... and sing
*Disclaimer: The following wisdom is very cliche ... but... "Be the change that you wish to see in the world."
― Mahatma Gandhi
🤖 My Programming Stats:


Resume
| Programming** Languages:** | JavaScript ES-6, NodeJS, React, HTML5, CSS3, SCSS, Bash Shell, Excel, SQL, NoSQL, MATLAB, Python, C++ |
|---|---|
| Databases: | PostgreSQL, MongoDB |
| Cloud: | Docker, AWS, Google App Engine, Netlify, Digital Ocean, Heroku, Azure Cloud Services |
| OS: | Linux, Windows (WSL), IOS |
| Agile: | GitHub, BitBucket, Jira, Confluence |
| IDEs: | VSCode, Visual Studio, Atom, Code Blocks, Sublime Text 3, Brackets |
| Relational Concepts: Hallandale Beach, FL | March 2020 - Present |
|---|---|
| Front End Web Developer | |
- Responsible for front-end development for a custom real estate application which provides sophisticated and fully customizable filtering to allow investors and real estate professionals to narrow in on exact search targets.
- Designed mock-up screens, wireframes, and workflows for intuitive user experience.
- Migrated existing multi-page user experience into singular page interfaces using React components.
- Participated in every stage of the design from conception through development and iterative improvement.
- Produced user stories and internal documentation for future site development and maintenance.
- Implemented modern frameworks including Bootstrap and Font-Awesome to give the site an aesthetic overhaul.
- Managed all test deployments using a combination of Digital Ocean and Netlify.
- Produced unit tests using a combination of Mocha and Chai.
- Injected Google Analytics to capture pertinent usage data to produce an insightful dashboard experience.
| Environment: | JavaScript, JQuery, React, HTML5 & CSS, Bootstrap, DOJO, Google Cloud, Bash Script |
|---|
| Cembre: Edison, NJ | Nov 2019 – Mar 2020 |
|---|---|
| Product Development Engineer | |
- Converted client' s product needs into technical specs to be sent to the development team in Italy.
- Reorganized internal file server structure.
- Conducted remote / in person system integration and product demonstrations.
- Presided over internal and end user software trainings in addition to producing the corresponding documentation.
- Served as the primary point of contact for troubleshooting railroad hardware and software in the North America.
| Environment: | Excel, AutoCAD, PowerPoint, Word |
|---|
| **B. S. Electrical Engineering, TCNJ, ** Ewing NJ | 2014 – 2019 |
|---|
Capstone Project – Team Lead
- Successfully completed and delivered a platform to digitize a guitar signal and perform filtering before executing frequency & time domain analysis to track a current performance against prerecorded performance.
- Implemented the Dynamic Time Warping algorithm in C++ and Python to autonomously activate or adjust guitar effect at multiple pre-designated section of performance.
| Environment: | C++, Python, MATLAB, PureData |
|---|
My Projects
<tr>
<th>Project Name</th>
<th>Skills used</th>
<th>Description</th>
</tr>
<tr>
<td><a href='https://web-dev-resource-hub.netlify.app/'>Web-Dev-Resource-Hub (blog)</a></td>
<td>Html, Css, javascript, Python, jQuery, React, FireBase, AWS S3, Netlify, Heroku, NodeJS, PostgreSQL, C++, Web Audio API</td>
<td>My blog site contains my resource sharing and blog site ... centered mostly on web development and just a bit of audio production / generally nerdy things I find interesting.</td>
</tr>
<tr>
<td><a href='https://project-showcase-bgoonz.netlify.app/'>Dynamic Guitar Effects Triggering Using A Modified Dynamic Time Warping Algorithm</a></td>
<td>C, C++, Python, Java, Pure Data, Matlab</td>
<td>Successfully completed and delivered a platform to digitize a guitar signal and perform filtering before executing frequency & time domain analysis to track a current performance against prerecorded performance.Implemented the Dynamic Time Warping algorithm in C++ and Python to autonomously activate or adjust guitar effect at multiple pre-designated section of performance.</td>
</tr>
<tr>
<td><a href="https://trusting-dijkstra-4d3b17.netlify.app/">Data Structures & Algorithms Interactive Learning Site</a></td>
<td>HTML, CSS, Javascript, Python, Java, jQuery, Repl.it-Database API</td>
<td>A interactive and comprehensive guide and learning tool for DataStructures and Algorithms ... concentrated on JS but with some examples in Python, C++ and Java as well</td>
</tr>
<tr>
<td><a href='https://mihirbegmusic.netlify.app/'>MihirBeg.com</a></td>
<td>Html, Css, Javascript, Bootstrap, FontAwesome, jQuery</td>
<td>A responsive and mobile friendly content promotion site for an Audio Engineer to engage with fans and potential clients</td>
</tr>
<tr>
<td><a href='https://tetris42.netlify.app/'>Tetris-JS</a></td>
<td>Html, Css, Javascript</td>
<td>The classic game of tetris implemented in plain javascipt and styled with a retro-futureistic theme</td>
</tr>
<tr>
<td><a href="https://githtmlpreview.netlify.app/">Git Html Preview Tool</a></td>
<td>Git, Javascript, CSS3, HTML5, Bootstrap, BitBucket</td>
<td>Loads HTML using CORS proxy, then process all links, frames, scripts and styles, and load each of them using CORS proxy, so they can be evaluated by the browser.</td>
</tr>
<tr>
<td><a href='https://project-showcase-bgoonz.netlify.app/'>Mini Project Showcase</a></td>
<td>HTML, HTML5, CSS, CSS3, Javascript, jQuery</td>
<td>add songs and play music, it also uses to store data in INDEXEDB Database by which we can play songs, if we not clear the catch then song will remain stored in database.</td>
</tr>

the method string.replaceAll(search, replaceWith) replaces all appearances of search string with replaceWith.
const str = 'this is a JSsnippets example';
const updatedStr = str.replace('example', 'snippet'); // 'this is a JSsnippets snippet'
The tricky part is that replace method replaces only the very first match of the substring we have passed:
const str = 'this is a JSsnippets example and examples are great';
const updatedStr = str.replace('example', 'snippet'); //'this is a JSsnippets snippet and examples are great'
In order to go through this, we need to use a global regexp instead:
const str = 'this is a JSsnippets example and examples are great';
const updatedStr = str.replace(/example/g, 'snippet'); //'this is a JSsnippets snippet and snippets are greatr'
but now we have new friend in town, replaceAll
const str = 'this is a JSsnippets example and examples are great';
const updatedStr = str.replaceAll('example', 'snippet'); //'this is a JSsnippets snippet and snippets are greatr'def fib_iter(n):
if n == 0:
return 0
if n == 1:
return 1
p0 = 0
p1 = 1
for i in range(n-1):
next_val = p0 + p1
p0 = p1
p1 = next_val
return next_val
for i in range(10):
print(f'{i}: {fib_iter(i)}')def quicksort(l):
# One of our base cases is an empty list or list with one element
if len(l) == 0 or len(l) == 1:
return l
# If we have a left list, a pivot point and a right list...
# assigns the return values of the partition() function
left, pivot, right = partition(l)
# Our sorted list looks like left + pivot + right, but sorted.
# Pivot has to be in brackets to be a list, so python can concatenate all the elements to a single list
return quicksort(left) + [pivot] + quicksort(right)
print(quicksort([]))
print(quicksort([1]))
print(quicksort([1,2]))
print(quicksort([2,1]))
print(quicksort([2,2]))
print(quicksort([5,3,9,4,8,1,7]))
print(quicksort([1,2,3,4,5,6,7]))
print(quicksort([9,8,7,6,5,4,3,2,1]))See Older Snippets!
will replace any spaces in file names with an underscore!
for file in *; do mv "$file" `echo $file | tr ' ' '_'` ; done
## TAKING IT A STEP FURTHER:
# Let's do it recursivley:
function RecurseDirs ()
{
oldIFS=$IFS
IFS=$'\n'
for f in "$@"
do
# YOUR CODE HERE!
[]
for file in *; do mv "$file" `echo $file | tr ' ' '_'` ; done
if [[ -d "${f}" ]]; then
cd "${f}"
RecurseDirs $(ls -1 ".")
cd ..
fi
done
IFS=$oldIFS
}
RecurseDirs "./"
Language: Javascript/Jquery
In combination with the script tag : <script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script> , this snippet will add a copy to clipboard button to all of your embedded
blocks.
$(document).ready(function() {
$('code, pre').append('<span class="command-copy" ><i class="fa fa-clipboard" aria-hidden="true"></i></span>');
$('code span.command-copy').click(function(e) {
var text = $(this).parent().text().trim(); //.text();
var copyHex = document.createElement('input');
copyHex.value = text
document.body.appendChild(copyHex);
copyHex.select();
document.execCommand('copy');
console.log(copyHex.value)
document.body.removeChild(copyHex);
});
$('pre span.command-copy').click(function(e) {
var text = $(this).parent().text().trim();
var copyHex = document.createElement('input');
copyHex.value = text
document.body.appendChild(copyHex);
copyHex.select();
document.execCommand('copy');
console.log(copyHex.value)
document.body.removeChild(copyHex);
});
})//APPEND-DIR.js
const fs = require('fs');
let cat = require('child_process').execSync('cat *').toString('UTF-8');
fs.writeFile('output.md', cat, (err) => {
if (err) throw err;
});const isAppleDevice = /Mac|iPod|iPhone|iPad/.test(navigator.platform);
console.log(isAppleDevice);
// Result: will return true if user is on an Apple device/*
function named intersection(firstArr) that takes in an array and
returns a function.
When the function returned by intersection is invoked
passing in an array (secondArr) it returns a new array containing the elements
common to both firstArr and secondArr.
*/
function intersection(firstArr) {
return (secondArr) => {
let common = [];
for (let i = 0; i < firstArr.length; i++) {
let el = firstArr[i];
if (secondArr.indexOf(el) > -1) {
common.push(el);
}
}
return common;
};
}
let abc = intersection(["a", "b", "c"]); // returns a function
console.log(abc(["b", "d", "c"])); // returns [ 'b', 'c' ]
let fame = intersection(["f", "a", "m", "e"]); // returns a function
console.log(fame(["a", "f", "z", "b"])); // returns [ 'f', 'a' ]/*
First is recurSum(arr, start) which returns the sum of the elements of arr from the index start till the very end.
Second is partrecurSum() that recursively concatenates the required sum into an array and when we reach the end of the array, it returns the concatenated array.
*/
//arr.length -1 = 5
// arr [ 1, 7, 12, 6, 5, 10 ]
// ind [ 0 1 2 3 4 5 ]
// ↟ ↟
// start end
function recurSum(arr, start = 0, sum = 0) {
if (start < arr.length) {
return recurSum(arr, start + 1, sum + arr[start]);
};
return sum;
}
function rPartSumsArr(arr, partSum = [], start = 0, end = arr.length - 1) {
if (start <= end) {
return rPartSumsArr(arr, partSum.concat(recurSum(arr, start)), ++start, end);
};
return partSum.reverse();
}
console.log('------------------------------------------------rPartSumArr------------------------------------------------')
console.log('rPartSumsArr(arr)=[ 1, 1, 5, 2, 6, 10 ]: ', rPartSumsArr(arr));
console.log('rPartSumsArr(arr1)=[ 1, 7, 12, 6, 5, 10 ]: ', rPartSumsArr(arr1));
console.log('------------------------------------------------rPartSumArr------------------------------------------------')
/*
------------------------------------------------rPartSumArr------------------------------------------------
rPartSumsArr(arr)=[ 1, 1, 5, 2, 6, 10 ]: [ 10, 16, 18, 23, 24, 25 ]
rPartSumsArr(arr1)=[ 1, 7, 12, 6, 5, 10 ]: [ 10, 15, 21, 33, 40, 41 ]
------------------------------------------------rPartSumArr------------------------------------------------
*/function camelToKebab(value) {
return value.replace(/([a-z])([A-Z])/g, "$1-$2").toLowerCase();
}function camel(str) {
return str.replace(/(?:^\w|[A-Z]|\b\w|\s+)/g, function(match, index) {
if (+match === 0) return ""; // or if (/\s+/.test(match)) for white spaces
return index === 0 ? match.toLowerCase() : match.toUpperCase();
});
}function addTwoNumbers(l1, l2) {
let result = new ListNode(0)
let currentNode = result
let carryOver = 0
while (l1 != null || l2 != null) {
let v1 = 0
let v2 = 0
if (l1 != null) v1 = l1.val
if (l2 != null) v2 = l2.val
let sum = v1 + v2 + carryOver
carryOver = Math.floor(sum / 10)
sum = sum % 10
currentNode.next = new ListNode(sum)
currentNode = currentNode.next
if (l1 != null) l1 = l1.next
if (l2 != null) l2 = l2.next
}
if (carryOver > 0) {
currentNode.next = new ListNode(carryOver)
}
return result.next
};//Function to test if a character is alpha numeric that is faster than a regular
//expression in JavaScript
let isAlphaNumeric = (char) => {
char = char.toString();
let id = char.charCodeAt(0);
if (
!(id > 47 && id < 58) && // if not numeric(0-9)
!(id > 64 && id < 91) && // if not letter(A-Z)
!(id > 96 && id < 123) // if not letter(a-z)
) {
return false;
}
return true;
};
console.log(isAlphaNumeric("A")); //true
console.log(isAlphaNumeric(2)); //true
console.log(isAlphaNumeric("z")); //true
console.log(isAlphaNumeric(" ")); //false
console.log(isAlphaNumeric("!")); //falsefunction replaceWords(str, before, after) {
if (/^[A-Z]/.test(before)) {
after = after[0].toUpperCase() + after.substring(1)
} else {
after = after[0].toLowerCase() + after.substring(1)
}
return str.replace(before, after)
}
console.log(replaceWords("Let us go to the store", "store", "mall")) //"Let us go to the mall"
console.log(replaceWords("He is Sleeping on the couch", "Sleeping", "sitting")) //"He is Sitting on the couch"
console.log(replaceWords("His name is Tom", "Tom", "john"))
//"His name is John"/*Simple Function to flatten an array into a single layer */
const flatten = (array) =>
array.reduce(
(accum, ele) => accum.concat(Array.isArray(ele) ? flatten(ele) : ele),
[]
);const isWeekday = (date) => date.getDay() % 6 !== 0;
console.log(isWeekday(new Date(2021, 0, 11)));
// Result: true (Monday)
console.log(isWeekday(new Date(2021, 0, 10)));
// Result: false (Sunday)function longestCommonPrefix(strs) {
let prefix = ''
if (strs.length === 0) return prefix
for (let i = 0; i < strs[0].length; i++) {
const character = strs[0][i]
for (let j = 0; j < strs.length; j++) {
if (strs[j][i] !== character) return prefix
}
prefix = prefix + character
}
return prefix
}
