+// MAGIC +// MAGIC
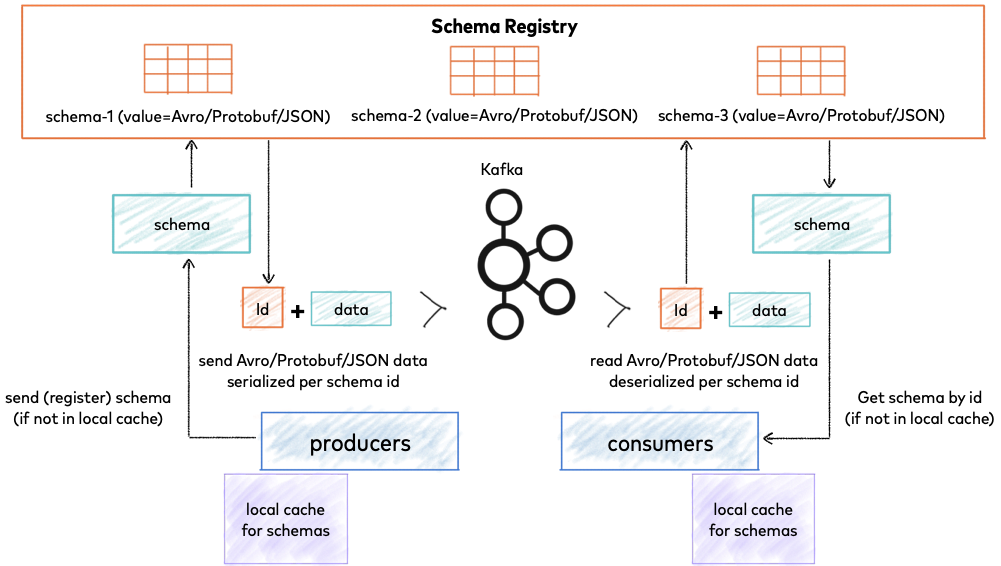 +
+// COMMAND ----------
+
+// These are the imports for authentication to the schema registry
+import io.confluent.kafka.schemaregistry.client.CachedSchemaRegistryClient
+import io.confluent.kafka.schemaregistry.client.rest.RestService
+import scala.jdk.CollectionConverters._
+
+val schemaRegistryRestService = new RestService(schemaRegistryUrl)
+
+val schemaRegistryProperties = Map(
+ "basic.auth.credentials.source" -> "USER_INFO",
+ "schema.registry.basic.auth.user.info" -> "%s:%s".format(confluentRegistryApiKey, confluentRegistrySecret)
+).asJava
+
+val schemaRegistryClient = new CachedSchemaRegistryClient(schemaRegistryRestService, 100, schemaRegistryProperties)
+
+// COMMAND ----------
+
+// MAGIC %md
+// MAGIC ## Streaming the Data from Confluent Kafka
+
+// COMMAND ----------
+
+// MAGIC %md
+// MAGIC ### Set up the Readstream
+
+// COMMAND ----------
+
+import org.apache.spark.sql.functions.udf
+import java.nio.ByteBuffer
+import org.apache.spark.sql.functions._
+import org.apache.spark.sql.avro.functions._
+
+// UDF that will decode the magic byte and schema identifier at the front of the Avro data
+// As of this writing the schema registry client provided by Confluent only supports int values for Schema IDs. If there are so many
+// schemas in the schema registry that the Schema ID value is larger than thet max for an int, the behavior of the client is unknown.
+
+val binaryToInt = udf((payload: Array[Byte]) => ByteBuffer.wrap(payload).getInt)
+
+// Set up the Readstream, include the authentication to Confluent Cloud for the Kafka topic.
+// Note the specific kafka.sasl.jaas.config value - on Databricks you have to use kafkashaded.org.apache.kafka.common... for that setting or else it will not find the PlainLoginModule.
+// If the kafka-clients-2.6.0.jar is installed on the cluster than a value of org.apache.kafka.common... will work fine.
+// The below is pulling from only one topic, but can be configured to pull from multiple with a comma-delimited set of topic names in the "subscribe" option
+// The below is also starting from a specific offset in the topic. You can specify both starting and ending offsets. If not specified then "latest" is the default for streaming.
+// The full syntax for the "startingOffsets" and "endingOffsets" options are to specify an offset per topic per partition.
+// Examples:
+// .option("startingOffsets", """{"topic1":{"0":23,"1":-2},"topic2":{"0":-2}}""") The -2 means "earliest" and -1 means "latest"
+// .option("endingOffsets", """{"topic1":{"0":50,"1":-1},"topic2":{"0":-1}}""") The -1 means "latest", -2 not allowed for endingOffsets
+
+val confluent_df = spark
+ .readStream
+ .format("kafka")
+ .option("kafka.bootstrap.servers", confluentBootstrapServers)
+ .option("kafka.security.protocol", "SASL_SSL")
+ .option("kafka.sasl.jaas.config", "kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='%s' password='%s';".format(confluentApiKey, confluentSecret))
+ .option("kafka.ssl.endpoint.identification.algorithm", "https")
+ .option("kafka.sasl.mechanism", "PLAIN")
+ .option("subscribe", confluentTopicName)
+ //.option("startingOffsets", "latest")
+ .option("checkpointPath", kafkaCheckPointPath)
+ .option("startingOffsets", """{"%s":{"0":25}}""".format(confluentTopicName))
+ .load()
+ .withColumn("fixedValue", expr("substring(value, 6, length(value)-5)"))
+ .withColumn("valueSchemaId", binaryToInt(expr("substring(value, 2, 4)")))
+ .select("valueSchemaId", "fixedValue")
+
+// COMMAND ----------
+
+//display(confluent_df)
+
+// COMMAND ----------
+
+// MAGIC %md
+// MAGIC ### Write out data from the stream using ForeachBatch
+
+// COMMAND ----------
+
+// Write out the parsed data to a Delta table
+import org.apache.spark.sql.DataFrame
+import org.apache.spark.sql.streaming.Trigger
+
+// This method will read the schema for each micro-batch - more resilient if the schema is expected to change often.
+confluent_df.writeStream
+ .foreachBatch {(df: DataFrame, epoch_id: Long) =>
+ // Cache this since we're going to access it several times
+ val cacheDf = df.cache
+
+ // Set the option for what to do with corrupt data - either stop on the first failure it finds (FAILFAST) or just set corrupt data to null (PERMISSIVE)
+ val fromAvroOptions = new java.util.HashMap[String, String]()
+ fromAvroOptions.put("mode", "PERMISSIVE")
+
+ // Function that will fetch a schema from the schema registry by ID
+ //def getSchema(id: Integer): String = {
+ // return schemaRegistryClient.getById(id).toString
+ //}
+
+ def getSubject(url: String): String = {scala.io.source.fromURL(url).mkString.split(",")(0).split(";")(1).replaceAll("\"","")}
+
+ val distinctValueSchemaIdDF = cacheDf.select("valueSchemaId").distinct()
+ // For each valueSchemaId get the schemas from the schema registry
+ for (valueRow <- distinctValueSchemaIdDF.collect) {
+ // Pull the schema for this schema ID
+ val currentValueSchemaId = sc.broadcast(valueRow.getAs[Int]("valueSchemaId"))
+ //val currentValueSchema = sc.broadcast(getSchema(currentValueSchemaId.value))
+ val customUrl = customUrlBasePath + currentValueSchemaId + customVersions
+ val currentSubject = getSubject(customUrl)
+
+ // Filter the batch to the rows that have this value schema ID
+ val filterValueDF = cacheDf.filter(cacheDf("valueSchemaId") === currentValueSchemaId.value)
+
+ // Parse the Avro data, break out the three columns and write the micro-batch
+ //val parsedDf = filterValueDF.select(from_avro($"fixedValue", currentValueSchema.value,fromAvroOptions).as('parsedValue))
+ val parsedDf = filterValueDF.select(from_avro($"fixedValue", currentSubject,schemaRegistryUrl,fromAvroOptions).as('parsedValue))
+ parsedDf
+ .write
+ .format("delta")
+ .mode("append")
+ .option("mergeSchema", "true")
+ .saveAsTable("raw_events_confluent")
+ }
+ }
+ .trigger(Trigger.Once)
+ .queryName("confluentAvroScalaForeachBatchStream")
+ .option("checkpointLocation", tableCheckPointPath)
+ .start()
+
+// COMMAND ----------
+
+// MAGIC %sql
+// MAGIC
+// MAGIC select * from raw_events_confluent
+
+// COMMAND ----------
+
+// These are the imports for authentication to the schema registry
+import io.confluent.kafka.schemaregistry.client.CachedSchemaRegistryClient
+import io.confluent.kafka.schemaregistry.client.rest.RestService
+import scala.jdk.CollectionConverters._
+
+val schemaRegistryRestService = new RestService(schemaRegistryUrl)
+
+val schemaRegistryProperties = Map(
+ "basic.auth.credentials.source" -> "USER_INFO",
+ "schema.registry.basic.auth.user.info" -> "%s:%s".format(confluentRegistryApiKey, confluentRegistrySecret)
+).asJava
+
+val schemaRegistryClient = new CachedSchemaRegistryClient(schemaRegistryRestService, 100, schemaRegistryProperties)
+
+// COMMAND ----------
+
+// MAGIC %md
+// MAGIC ## Streaming the Data from Confluent Kafka
+
+// COMMAND ----------
+
+// MAGIC %md
+// MAGIC ### Set up the Readstream
+
+// COMMAND ----------
+
+import org.apache.spark.sql.functions.udf
+import java.nio.ByteBuffer
+import org.apache.spark.sql.functions._
+import org.apache.spark.sql.avro.functions._
+
+// UDF that will decode the magic byte and schema identifier at the front of the Avro data
+// As of this writing the schema registry client provided by Confluent only supports int values for Schema IDs. If there are so many
+// schemas in the schema registry that the Schema ID value is larger than thet max for an int, the behavior of the client is unknown.
+
+val binaryToInt = udf((payload: Array[Byte]) => ByteBuffer.wrap(payload).getInt)
+
+// Set up the Readstream, include the authentication to Confluent Cloud for the Kafka topic.
+// Note the specific kafka.sasl.jaas.config value - on Databricks you have to use kafkashaded.org.apache.kafka.common... for that setting or else it will not find the PlainLoginModule.
+// If the kafka-clients-2.6.0.jar is installed on the cluster than a value of org.apache.kafka.common... will work fine.
+// The below is pulling from only one topic, but can be configured to pull from multiple with a comma-delimited set of topic names in the "subscribe" option
+// The below is also starting from a specific offset in the topic. You can specify both starting and ending offsets. If not specified then "latest" is the default for streaming.
+// The full syntax for the "startingOffsets" and "endingOffsets" options are to specify an offset per topic per partition.
+// Examples:
+// .option("startingOffsets", """{"topic1":{"0":23,"1":-2},"topic2":{"0":-2}}""") The -2 means "earliest" and -1 means "latest"
+// .option("endingOffsets", """{"topic1":{"0":50,"1":-1},"topic2":{"0":-1}}""") The -1 means "latest", -2 not allowed for endingOffsets
+
+val confluent_df = spark
+ .readStream
+ .format("kafka")
+ .option("kafka.bootstrap.servers", confluentBootstrapServers)
+ .option("kafka.security.protocol", "SASL_SSL")
+ .option("kafka.sasl.jaas.config", "kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='%s' password='%s';".format(confluentApiKey, confluentSecret))
+ .option("kafka.ssl.endpoint.identification.algorithm", "https")
+ .option("kafka.sasl.mechanism", "PLAIN")
+ .option("subscribe", confluentTopicName)
+ //.option("startingOffsets", "latest")
+ .option("checkpointPath", kafkaCheckPointPath)
+ .option("startingOffsets", """{"%s":{"0":25}}""".format(confluentTopicName))
+ .load()
+ .withColumn("fixedValue", expr("substring(value, 6, length(value)-5)"))
+ .withColumn("valueSchemaId", binaryToInt(expr("substring(value, 2, 4)")))
+ .select("valueSchemaId", "fixedValue")
+
+// COMMAND ----------
+
+//display(confluent_df)
+
+// COMMAND ----------
+
+// MAGIC %md
+// MAGIC ### Write out data from the stream using ForeachBatch
+
+// COMMAND ----------
+
+// Write out the parsed data to a Delta table
+import org.apache.spark.sql.DataFrame
+import org.apache.spark.sql.streaming.Trigger
+
+// This method will read the schema for each micro-batch - more resilient if the schema is expected to change often.
+confluent_df.writeStream
+ .foreachBatch {(df: DataFrame, epoch_id: Long) =>
+ // Cache this since we're going to access it several times
+ val cacheDf = df.cache
+
+ // Set the option for what to do with corrupt data - either stop on the first failure it finds (FAILFAST) or just set corrupt data to null (PERMISSIVE)
+ val fromAvroOptions = new java.util.HashMap[String, String]()
+ fromAvroOptions.put("mode", "PERMISSIVE")
+
+ // Function that will fetch a schema from the schema registry by ID
+ //def getSchema(id: Integer): String = {
+ // return schemaRegistryClient.getById(id).toString
+ //}
+
+ def getSubject(url: String): String = {scala.io.source.fromURL(url).mkString.split(",")(0).split(";")(1).replaceAll("\"","")}
+
+ val distinctValueSchemaIdDF = cacheDf.select("valueSchemaId").distinct()
+ // For each valueSchemaId get the schemas from the schema registry
+ for (valueRow <- distinctValueSchemaIdDF.collect) {
+ // Pull the schema for this schema ID
+ val currentValueSchemaId = sc.broadcast(valueRow.getAs[Int]("valueSchemaId"))
+ //val currentValueSchema = sc.broadcast(getSchema(currentValueSchemaId.value))
+ val customUrl = customUrlBasePath + currentValueSchemaId + customVersions
+ val currentSubject = getSubject(customUrl)
+
+ // Filter the batch to the rows that have this value schema ID
+ val filterValueDF = cacheDf.filter(cacheDf("valueSchemaId") === currentValueSchemaId.value)
+
+ // Parse the Avro data, break out the three columns and write the micro-batch
+ //val parsedDf = filterValueDF.select(from_avro($"fixedValue", currentValueSchema.value,fromAvroOptions).as('parsedValue))
+ val parsedDf = filterValueDF.select(from_avro($"fixedValue", currentSubject,schemaRegistryUrl,fromAvroOptions).as('parsedValue))
+ parsedDf
+ .write
+ .format("delta")
+ .mode("append")
+ .option("mergeSchema", "true")
+ .saveAsTable("raw_events_confluent")
+ }
+ }
+ .trigger(Trigger.Once)
+ .queryName("confluentAvroScalaForeachBatchStream")
+ .option("checkpointLocation", tableCheckPointPath)
+ .start()
+
+// COMMAND ----------
+
+// MAGIC %sql
+// MAGIC
+// MAGIC select * from raw_events_confluent